
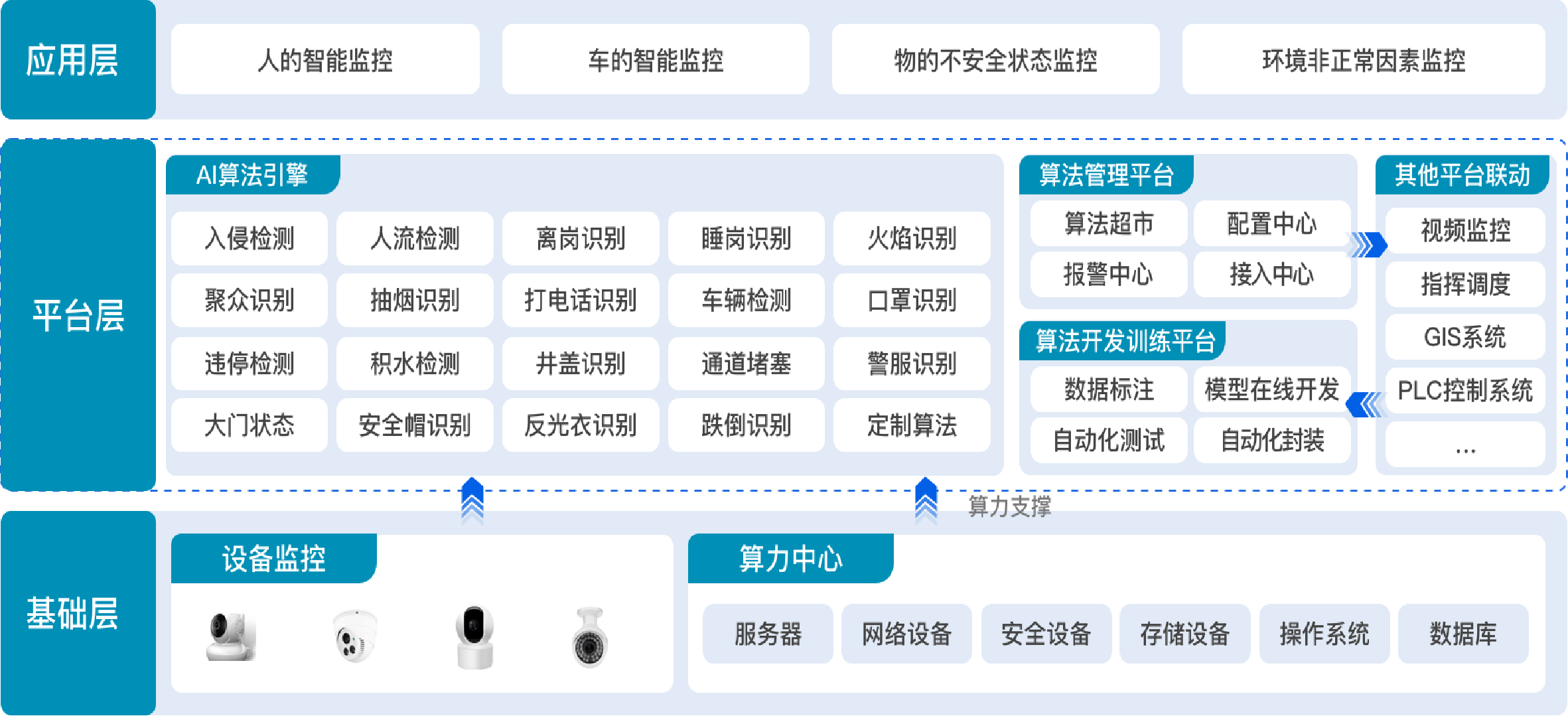
AI 智算模组相较于传统 GPU,在架构设计、能效表现、场景适配等方面展现出显著优势,尤其在边缘计算、端侧设备等领域更具竞争力。以下是基于最新技术动态的详细对比分析:
一、架构设计:专用化 vs 通用化
AI 智算模组的专用架构
AI 智算模组以 NPU(神经网络处理器)为核心,针对深度学习推理中的矩阵乘法、卷积运算等高频操作进行硬件级优化。例如,算丰 SM5 模组搭载的 BM1684 芯片采用乘加(MAC)阵列直接连接乘法器和加法器,形成 “计算管道”,可在一条指令内完成复杂的矩阵运算,减少数据搬运开销,推理时延降低至传统 GPU 的 1/3。这种专用设计使 SM5 在处理 16 路 1080P 视频实时分析时,算力利用率比传统 GPU 提升 3 倍。

传统 GPU 的通用架构瓶颈
GPU 最初为图形渲染设计,虽通过 Tensor Core 等技术增强了 AI 计算能力,但其架构仍需兼顾浮点运算、图形处理等通用任务。例如,NVIDIA A100 在执行矩阵乘法时,需经历数据加载、缓存读写、计算器调用等多步骤,导致延迟较高。在处理 32B 参数大模型时,GPU 因数据频繁搬运至显存,性能下降约 25%。
二、能效表现:低功耗革命
AI 智算模组的能效比优势
AI 智算模组通过架构优化和制程工艺革新,实现了 “高能效比” 突破。例如,腾视科技 TS-SG-SM7 系列在 32TOPS INT8 算力下功耗仅 18W,单位算力功耗比 NVIDIA A100(400W/312 TOPS FP16)低 90% 以上。爱簿 E300 模组采用异构计算架构,在 50TOPS 算力下实现 102GB/s 内存带宽,能效比传统 GPU 提升 5 倍,可在 - 40℃至 + 85℃宽温环境中稳定运行。
传统 GPU 的高功耗痛点
传统 GPU 的高性能依赖于庞大的计算核心和高带宽显存,导致功耗居高不下。例如,NVIDIA A100 的 TDP 为 400W,而 H100 虽能效比提升,但功耗仍达 700W,仅适用于数据中心等具备充足供电和散热条件的场景。在边缘场景中,GPU 的高功耗可能导致设备续航缩短或需额外部署散热设备,显著增加成本。
三、场景适配:边缘智能的核心载体
AI 智算模组的边缘原生特性
AI 智算模组专为边缘环境设计,具备 “小体积、高集成” 特点。例如,算丰 SM5 尺寸仅为 62×58mm(约 2/3 信用卡大小),集成 PCIe、USB 等接口,可直接嵌入无人机、工业摄像头等设备,支持 32 路 1080P 视频解码和实时分析。腾视科技 TS-SG-SM7 系列在煤矿井下 50℃高湿环境中连续运行 12 个月,故障率为 0,完美应对工业现场的严苛挑战。
传统 GPU 的边缘部署局限
传统 GPU 体积大、功耗高,难以适配边缘设备的空间和能源限制。例如,NVIDIA Jetson AGX Orin 虽为边缘优化,但其尺寸(100×150mm)和功耗(50W)仍显著高于 AI 智算模组,且需额外散热模块。在智慧城市项目中,部署 100 台 AI 智算模组的边缘节点集群,年耗电量较传统 GPU 方案减少 12 万度,硬件成本降低 28 万元。

四、开发门槛与生态支持
AI 智算模组的低代码开发
头部厂商提供全栈式开发工具链,显著降低技术门槛。例如,算能 BMNNSDK2 支持模型自动量化、编译和部署,开发者可直接调用预训练模型(如 YOLOv8、ResNet),无需深入底层硬件编程。爱簿 E300 提供低代码平台,非专业人员可通过拖拽组件快速构建 AI 应用,开发周期缩短 60%。
传统 GPU 的开发复杂性
GPU 开发依赖 CUDA、cuDNN 等专用工具链,需掌握复杂的并行编程技巧。例如,在 GPU 上部署大模型需手动优化显存分配和内核调度,开发周期长达数周。此外,GPU 对国产操作系统和框架的适配性较弱,在国产化替代场景中存在兼容性风险。
五、政策与产业趋势
AI 智算模组的国产化红利
中国 “东数西算” 工程和具身智能行动计划明确支持边缘算力下沉,地方政府设立专项资金(如广东省 35 亿元产业基金)推动国产 AI 模组研发。算能、华为昇腾等厂商已实现从芯片到驱动的全链自研,国产化适配率超 95%,并通过工业级认证(如 IEC 61000-4 电磁兼容标准)。
传统 GPU 的供应链挑战
传统 GPU 依赖进口芯片和高端制程,面临地缘政治风险。例如,NVIDIA A100、H100 的出口受限,导致国内企业在大模型训练和边缘部署中存在供应链瓶颈。相比之下,国产 AI 智算模组可通过成熟的 14nm/28nm 工艺量产,供货稳定性更高。
总结
AI 智算模组凭借专用架构、低功耗设计、边缘原生特性、低代码开发等优势,在工业质检、智慧城市、医疗影像等领域实现了对传统 GPU 的替代。未来,随着大模型轻量化技术(如模型量化、知识蒸馏)和多模态融合技术的发展,AI 智算模组将进一步释放边缘算力潜力,成为推动 AI 从云端向端侧渗透的核心引擎。传统 GPU 则仍将在大规模模型训练和高端图形处理领域保持优势,但在边缘智能、国产替代等场景中,AI 智算模组已展现出不可替代的竞争力。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















