
一、算力堆叠的瓶颈与能效革命的必然转向
1.1 传统算力堆叠的三大核心痛点
能效比失衡:万亿参数大模型训练单次能耗可达 1287MWh,相当于 1000 户家庭年用电量
资源利用率低:传统集群 GPU 利用率普遍低于 30%,算力浪费严重
扩展性瓶颈:万卡以上集群通信延迟激增,性能加速比远低于线性增长
1.2 能效革命的核心内涵
维度 | 算力堆叠思维 | 能效革命思维 |
核心目标 | 单纯提升算力规模 | 算力密度 × 能效比 × 利用率三维优化 |
技术路径 | 硬件堆砌 + 简单扩容 | 全栈协同 + 架构创新 + 算法优化 |
资源调度 | 静态分配 | 动态适配 + 智能调度 |
成本模型 | 以硬件投入为核心 | 全生命周期 TCO 最优 |
二、国产算力平台全栈架构创新
2.1 硬件层:从单点性能到超节点集群革命
超节点架构突破
华为昇腾 384 超节点:全液冷散热 + 光互联技术,算力密度提升 3 倍,能效比优化 40%,单节点性能超越英伟达 NVL72;
中科曙光 scaleX640:单节点集成 640 张算力卡,万卡集群总规模达 10240 块 AI 加速卡,总算力超 5EFlops;
摩尔线程 MTT C256:计算与交换一体化高密设计,算力密度提升 50%,支持 FP4~FP64 全精度计算;

国产芯片生态成熟
华为昇腾 910B、海光 DCU、寒武纪思元 370 等芯片完成 30 + 主流大模型深度适配,适配效率提升 3 倍;
国产芯片性能突破:寒武纪思元 690 单卡算力达 1.2PFlops,较上一代提升 50%;
2.2 网络层:打破通信瓶颈的关键一跃
高速互联技术革新
曙光 scaleFabric:400G 原生 RDMA 网络,延迟 < 1 微秒,通信性能提升 2.33 倍,成本降低 30%;
中国移动智算中心:sMT 组网技术实现 1.6Tbps 带宽、15TB/s 吞吐,支持万卡并行训练 + 分钟级断点续训;
跨域混训技术:DeepLink 实现 1500 公里异构智算中心算力协同,解决算力分布不均问题;
2.3 软件层:全栈可控的智能调度体系
分布式训练引擎突破
华为 MindSpore、摩尔线程 MUSA 5.0 等自主框架深度适配国产硬件,性能提升 40%+;
自研分布式训练引擎支持算子级优化,实现万亿参数模型高效训练;
模型优化工具链
硬件感知型优化工具:自动将 PyTorch/TensorFlow 模型转换为国产芯片适配格式,显存占用降低 50%+;
量化剪枝技术:将 32 位浮点模型转为 8 位整数,精度损失可控前提下能耗降低 75%;
MoE 架构优化:动态激活专家层,计算资源利用率提升至 80%+;
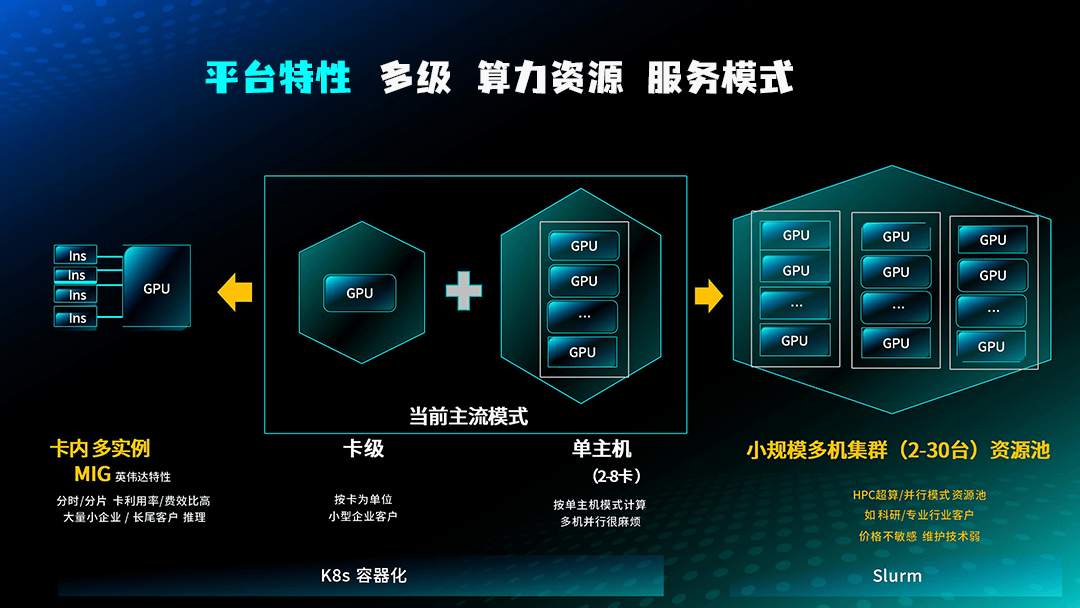
三、典型厂商解决方案与行业落地案例
3.1 头部厂商全栈解决方案
厂商 | 核心平台 | 关键能力 | 典型应用 |
华为 + 讯飞 | 飞星一号 | 万亿参数模型训练,存算网全栈国产化 | 智能语音、认知大模型 |
中科曙光 | scaleX 万卡集群 | 科学计算 + AI 融合,10 万卡级扩展能力 | 气象预测、药物研发 |
商汤科技 | 算电智能调度平台 | 算力 + 电力数据打通,利用率达 80% | 智慧城市、自动驾驶 |
摩尔线程 | 花港架构 + MUSA 5.0 | 推理性能突破,Prefill 吞吐 4000 tokens/s | 内容生成、智能客服 |
3.2 标志性行业案例
甘肃庆阳十万卡国产算力集群:2025 年底投产,支撑 “东数西算” 工程深化落地,实现国产硬件全面支撑大模型全生命周期开发;
中国移动国家智算中心:部署 1.8 万张国产 AI 加速卡,实现 “万卡并行训练 + 分钟级断点续训”,支撑万亿参数模型训练;
神算大模型平台:基于华为昇腾构建全栈自主架构,完成准万亿参数模型训练,标志国产硬件具备超大规模模型支撑能力;
四、全栈提速的关键技术突破
4.1 能效优化核心技术组合
散热与供电创新
全液冷技术:PUE 降至 1.1 以下,较风冷系统节能 30%+,已成为万卡集群标配;
智能供电管理:根据负载动态调整供电策略,闲置节点功耗降低 50%;
计算架构创新
P-D 分离架构:Prefill 与 Decode 阶段分离,推理吞吐提升 75%,特定场景提升 5.25 倍;
MoE 动态激活:仅激活 10-20% 专家层,计算量减少 80%,同时保持模型性能;
KVCache 优化:缓存关键值对,推理延迟降低 60%,吞吐量提升 3 倍;
4.2 算力调度智能化升级
算力匹配指数:根据模型参数量、数据吞吐量自动分配最优算力组合,资源利用率提升至 70%+;
动态负载均衡:实时监控算力状态,任务迁移时间 < 10 秒,保障集群稳定运行;
断点续训技术:分钟级恢复万亿参数模型训练状态,避免算力浪费;
五、从技术突破到产业落地:三大转型方向
5.1 从通用算力到场景化定制
行业专用算力解决方案:金融风控、生物医药、自动驾驶等领域定制化算力平台,性能提升 30-50%;
边缘 + 核心协同架构:核心节点负责训练,边缘节点负责推理,端到端延迟降低 70%;
5.2 从自主可控到生态开放
国产算力平台已完成与 Qwen 3、Baichuan 4、Llama 4 中文版等主流大模型深度适配;
开放软件栈:摩尔线程 MUSA 5.0 开源核心组件,华为 MindSpore 构建开源社区,降低开发者门槛;
5.3 从性能导向到 TCO 最优
全生命周期成本模型:硬件投入占比从 70% 降至 50%,运维与能效成本优化成为核心竞争力;
绿色算力认证:国产平台率先通过国际绿色算力标准,PUE<1.2,碳减排效果显著;

六、总结与展望
国产大模型算力平台正经历从 “堆硬件” 到 “提能效” 的质变,通过超节点硬件架构 + 高速互联网络 + 全栈软件协同 + 智能调度算法的四维创新,实现了算力密度提升 3-5 倍、能效比优化 40%+、资源利用率从 30% 提升至 80% 的跨越式发展。
下一步发展重点将聚焦:
进一步突破10 万卡级集群扩展能力,支撑 10 万亿参数模型训练;
推动存算一体与近存计算技术成熟,解决内存墙瓶颈;
构建算力 - 算法 - 数据协同优化体系,实现大模型训练推理全链路效率革命;
关键数据速览
算力密度提升:3-5 倍(华为昇腾、摩尔线程);
能效比优化:40%+(液冷 + 架构创新);
资源利用率:从 30%→80%+(智能调度 + MoE 优化);
通信性能提升:2.33 倍(400G RDMA 网络);
模型适配效率:提升3 倍(国产芯片生态);
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















