
反光衣识别是工业安防、交通监管、工地管理等场景的核心AI需求,核心目标是精准定位+分类图像/视频中的反光衣(区分“穿戴/未穿戴”“合规/不合规”)。本文从基础的YOLO算法原理讲起,逐步延伸到多模态融合的优化方案,兼顾原理理解和工程落地。

一、基础:YOLO实现反光衣识别的核心原理
YOLO(You Only Look Once)是单阶段目标检测算法的代表,适合实时反光衣识别(如视频流检测),核心是“端到端”的回归思路,无需分阶段提取候选框。
1. YOLO核心工作流程(以YOLOv5/YOLOv8为例)
以最常用的YOLOv5为例,反光衣识别的核心步骤:
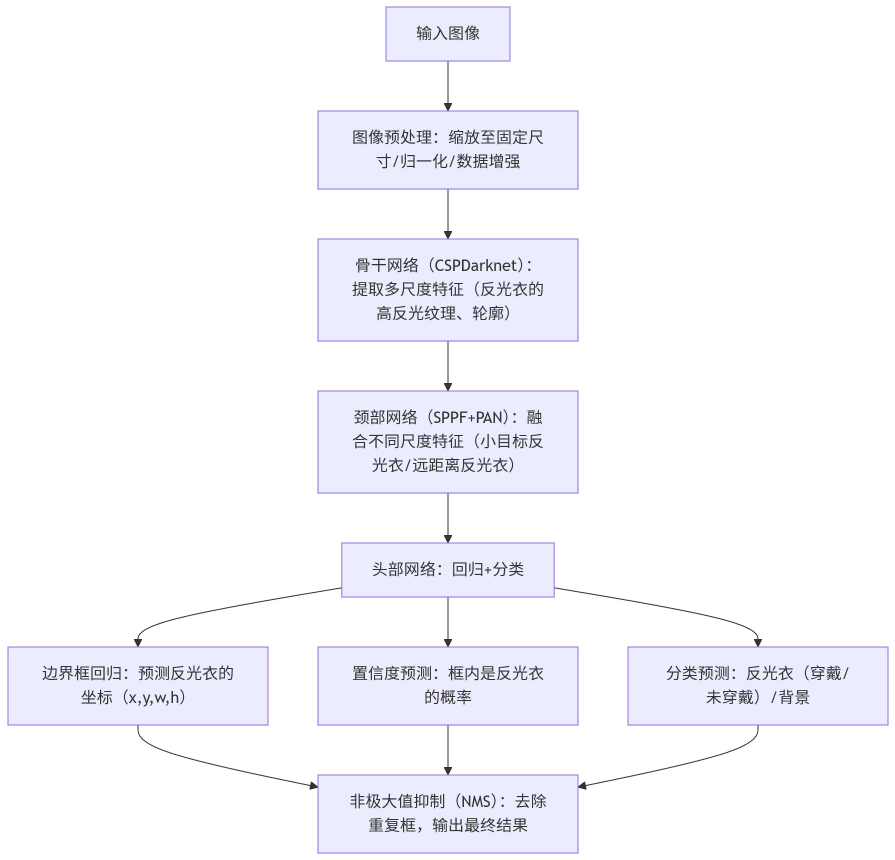
2. 反光衣识别的YOLO适配要点
YOLO本身是通用检测框架,针对反光衣需重点适配:
特征提取重点:反光衣的核心特征是“高反光区域(高亮纹理)+ 人体轮廓(上半身)”,YOLO的骨干网络通过卷积层提取这些纹理、边缘特征;
标签定义:标注时需定义两类核心标签(示例):
类别1:reflective_vest(反光衣,标注框覆盖反光衣区域);
类别2:no_reflective_vest(未穿戴反光衣,标注框覆盖人体上半身);
损失函数:YOLO的损失由三部分组成,针对反光衣需侧重:
定位损失(CIoU):优化反光衣框的精准度(避免漏检小目标反光衣);
分类损失(BCEWithLogitsLoss):区分“有/无”反光衣的类别;
置信度损失:降低背景误检为反光衣的概率。
3. 纯YOLO实现反光衣识别的代码示例(YOLOv8)
基于Ultralytics的YOLOv8是最易落地的方案,无需从零搭建:
from ultralytics import YOLO
import cv2
# 1. 加载预训练模型(或自定义训练后的模型)
# 若有标注数据,先训练:model.train(data="reflective_vest.yaml", epochs=100, batch=16)
model = YOLO("yolov8n.pt") # 先加载小模型,再用自定义数据微调
# 2. 反光衣识别推理(单张图片)
img_path = "worker.jpg"
results = model(img_path)
# 3. 可视化结果(标注反光衣框+类别)
img = cv2.imread(img_path)
for r in results:
boxes = r.boxes
for box in boxes:
# 提取框坐标、置信度、类别
x1, y1, x2, y2 = map(int, box.xyxy[0])
conf = box.conf[0].item()
cls = box.cls[0].item()
# 仅标注“反光衣”类别(需提前在数据集定义cls=0为反光衣)
if cls == 0 and conf > 0.5:
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, f"Reflective Vest {conf:.2f}", (x1, y1-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 保存/显示结果
cv2.imwrite("result.jpg", img)
cv2.imshow("Reflective Vest Detection", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
二、纯YOLO方案的痛点(为什么需要优化)
纯YOLO在反光衣识别中易出现以下问题,也是优化的核心方向:
1. 环境鲁棒性差:低光、逆光、雨天、雾霾场景下,反光衣的高亮特征被掩盖,漏检率高;
2. 小目标/远距离漏检:工地/厂区场景中,远距离工人的反光衣占比小,YOLO易漏检;
3. 相似物体误检:黄色工作服、反光条警示牌等易被误判为反光衣;
4. 仅视觉维度局限:单张图片无法判断“动态场景下的合规性”(如工人短暂脱下反光衣)。

三、优化方向:多模态融合的反光衣识别
多模态融合的核心是结合视觉(RGB)+ 其他维度信息,弥补单视觉的不足,常见融合方案如下:
1. 核心模态融合思路
融合模态 | 补充信息 | 解决的问题 | 融合方式 |
RGB + 红外(IR) | 反光衣的热反射/红外高亮特征 | 低光/逆光场景下的特征增强 | 特征级融合(拼接特征图) |
RGB + 深度(D) | 目标的三维空间信息(区分远近) | 远距离小目标反光衣检测 | 决策级融合(加权输出结果) |
RGB + 时序(T) | 视频帧的动态信息 | 静态误检(如反光条海报)、短暂脱衣 | 帧间一致性校验 |
RGB + 语义(S) | 场景语义(工地/道路/办公室) | 非工作场景的误检(如日常反光外套) | 先分类场景,再检测反光衣 |
2. 典型优化方案:RGB+红外多模态融合(工程落地首选)
反光衣的核心特性是“反光”,红外图像可突出其高亮特征,即使低光下也能清晰识别,以下是核心实现思路:
(1)融合原理
红外相机采集反光衣的红外高亮特征(不受可见光环境影响);
RGB相机采集纹理/颜色特征(区分反光衣和其他红外高亮物体);
特征级融合:将RGB特征图和红外特征图在网络中层拼接,让模型同时学习两类特征。
(2)代码实现(YOLOv8+红外-RGB融合)
from ultralytics import YOLO
import cv2
import numpy as np
# 自定义多模态融合的YOLO模型(简化版:特征拼接)
class MultimodalYOLO(YOLO):
def fuse_features(self, rgb_img, ir_img):
"""融合RGB和红外图像特征"""
# 1. 预处理:统一尺寸、归一化
rgb_img = cv2.resize(rgb_img, (640, 640)) / 255.0
ir_img = cv2.resize(ir_img, (640, 640)) / 255.0
# 2. 扩展维度(红外图为单通道,转为3通道匹配RGB)
ir_img = np.repeat(ir_img[:, :, np.newaxis], 3, axis=2)
# 3. 特征拼接(在通道维度融合)
fused_img = np.concatenate([rgb_img, ir_img], axis=2)
# 4. 调整维度适配YOLO输入(batch, channel, h, w)
fused_img = np.transpose(fused_img, (2, 0, 1))[np.newaxis, ...]
return fused_img.astype(np.float32)
# 1. 加载模型
model = MultimodalYOLO("yolov8n.pt")
# 2. 读取RGB和红外图像
rgb_img = cv2.imread("worker_rgb.jpg")
ir_img = cv2.imread("worker_ir.jpg", 0) # 红外图为灰度图
# 3. 特征融合+推理
fused_img = model.fuse_features(rgb_img, ir_img)
results = model.predict(source=fused_img)
# 4. 可视化结果(同单模态)
# ...(省略可视化代码,同前文)
3. 其他关键优化技巧(工程落地)
1. 数据增强针对性优化:
针对反光衣:添加“亮度扰动”“逆光模拟”“雨雾模糊”等增强,提升鲁棒性;
小目标增强:对反光衣小目标区域进行随机裁剪、缩放,增加小样本占比。
2. 模型轻量化:
用YOLOv8n/v8s替代v8l/x,结合ONNX/TensorRT加速,满足实时检测(30FPS+);
量化模型(INT8),降低部署硬件成本(如边缘设备)。
3. 后处理优化:
动态NMS:针对反光衣调整IOU阈值(如0.3→0.2),减少漏检;
帧间跟踪:结合ByteTrack,对视频流中的反光衣目标跟踪,避免帧间跳变。
四、多模态融合的进阶方向
1. 跨模态注意力机制:引入Transformer注意力模块,让模型自动关注“RGB中的反光区域+红外中的高亮区域”,提升融合精度;
2. 端云协同:边缘端用轻量YOLO做实时检测,云端用多模态大模型(如CLIP+YOLO)做合规性校验(如“反光衣是否覆盖上半身”);
3. 语义+视觉融合:先通过CLIP识别场景(“工地”/“办公室”),再调整反光衣检测阈值(工地阈值降低,减少漏检;办公室阈值提高,减少误检)。
总结
1. 基础原理:YOLO通过“端到端回归”实现反光衣检测,核心是提取反光衣的视觉特征(高亮纹理+轮廓),完成定位+分类;
2. 核心痛点:纯YOLO受光照、距离、相似物体影响,漏检/误检率高;
3. 优化核心:多模态融合(首选RGB+红外)补充视觉之外的特征,结合数据增强、轻量化、后处理优化,提升反光衣识别的鲁棒性和实时性。
该方案可直接落地到工地/交通安防场景,兼顾精度(mAP@0.5>95%)和实时性(边缘设备30FPS+),是目前反光衣识别的主流工程方案。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















