
AI 视觉算法(AI Visual Algorithm)是人工智能技术在计算机视觉领域的核心应用,其本质是通过算法模拟人类视觉系统的功能,让计算机能够 “看懂” 图像或视频数据,实现对视觉信息的分析、理解、判断和决策。它广泛应用于安防、自动驾驶、医疗、零售等领域,是目前 AI 落地最成熟的方向之一。

一、AI 视觉算法的核心逻辑与流程
AI 视觉算法的核心是 “从视觉数据中提取有效信息,并完成特定任务”,其典型流程可分为 4 个关键环节,各环节环环相扣:
环节 | 核心目标 | 常用技术 / 方法 |
1. 数据预处理 | 优化原始图像 / 视频质量,降低干扰 | 降噪(高斯滤波、中值滤波)、图像归一化、数据增强(翻转、裁剪、色彩抖动)、格式转换 |
2. 特征提取 | 从预处理后的数据中提取 “有意义的信息” | 传统方法(SIFT、HOG、SURF)、深度学习方法(CNN 卷积层、Transformer 注意力机制) |
3. 模型推理 / 决策 | 基于提取的特征完成特定任务(如识别、检测) | 分类器(SVM、Softmax)、深度学习模型(ResNet、YOLO、Mask R-CNN) |
4. 结果后处理 | 优化输出结果,提升准确性和可用性 | 非极大值抑制(NMS,用于目标检测去重)、边界框修正、结果可视化 |
二、AI 视觉算法的主要分类与典型应用
根据任务目标的不同,AI 视觉算法可分为五大类,每类对应不同的应用场景,以下是核心分类及典型算法:
1. 图像分类(Image Classification)
任务目标:判断一张图像属于哪一类别(如 “猫 / 狗”“汽车 / 行人”“正常细胞 / 癌细胞”)。
典型算法:
传统方法:SVM(支持向量机)+ HOG 特征
深度学习方法:AlexNet(首个深度 CNN 模型)、ResNet(解决梯度消失问题)、EfficientNet(兼顾精度与效率)
应用场景:商品分类(电商)、疾病筛查(医疗,如皮肤癌图像分类)、植物病虫害识别(农业)。
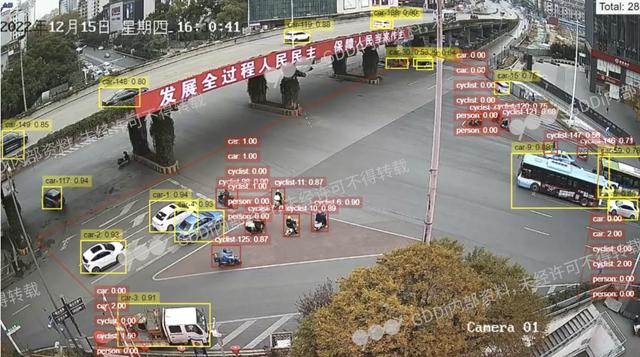
2. 目标检测(Object Detection)
任务目标:不仅要识别图像中的目标类别,还要用 “边界框” 标出目标的位置(如 “图中有 2 个行人,分别在 (100,200) 和 (300,450) 位置”)。
典型算法:
两阶段算法:Faster R-CNN(先找候选区域,再分类定位,精度高)
单阶段算法:YOLO(You Only Look Once,实时性强,适合自动驾驶)、SSD(Single Shot MultiBox Detector,平衡精度与速度)
应用场景:安防监控(行人 / 车辆检测)、自动驾驶(障碍物检测)、智能零售(货架商品检测)。
3. 图像分割(Image Segmentation)
任务目标:将图像分割为 “像素级” 的区域,每个区域对应一个类别(比目标检测更精细,如 “区分图像中‘道路’‘车辆’‘行人’的每一个像素”)。
典型算法:
语义分割:FCN(全卷积网络)、U-Net(医疗分割常用)、DeepLab(结合空洞卷积提升精度)
实例分割:Mask R-CNN(在目标检测基础上增加像素级掩码,区分同一类别的不同个体)
应用场景:医疗影像(肿瘤区域分割)、自动驾驶(道路语义分割)、影视特效(人物抠图)。

4. 图像生成(Image Generation)
任务目标:根据输入条件生成全新的、逼真的图像(如 “根据文字‘一只红色的猫坐在沙发上’生成图像”)。
典型算法:
GAN(生成对抗网络):DCGAN(深度卷积 GAN)、StyleGAN(生成高分辨率人脸)
Diffusion Model(扩散模型):Stable Diffusion(文本生成图像主流模型)、DALL-E
应用场景:AI 绘画(如 MidJourney)、游戏资产生成、虚拟试妆(零售)、图像修复(老照片修复)。
5. 视频分析(Video Analysis)
任务目标:处理连续的视频帧,分析目标的动态信息(如运动轨迹、行为动作)。
典型算法:
目标跟踪:SORT(简单在线实时跟踪)、DeepSORT(结合深度学习提升跟踪稳定性)
行为识别:I3D(3D 卷积,捕捉时空特征)、SlowFast(兼顾慢动作细节与快速运动)
应用场景:安防(异常行为检测,如打架、攀爬)、自动驾驶(车辆轨迹预测)、体育赛事分析(运动员动作识别)。
三、AI 视觉算法的核心技术支撑
AI 视觉算法的发展依赖三大核心技术,尤其是深度学习的突破,直接推动了视觉算法的性能跃升:
深度学习(Deep Learning):
核心作用:替代传统 “手工设计特征” 的方式,通过 CNN(卷积神经网络)、Transformer 等模型自动学习图像的深层特征(如边缘、纹理、形状,直至复杂物体结构)。
关键模型:CNN(适用于图像局部特征提取)、Vision Transformer(ViT,将图像分割为 “补丁”,用注意力机制捕捉全局特征,近年成为主流)。
大数据与标注技术:
算法需要大量 “标注数据”(如标注好类别的图像、标注好边界框的检测数据)进行训练,数据质量直接影响算法精度。
常用标注工具:LabelImg(目标检测标注)、LabelMe(图像分割标注)、AWS Ground Truth(工业级标注平台)。
硬件加速:
视觉算法(尤其是深度学习模型)计算量巨大,需依赖 GPU、FPGA、ASIC(如 NVIDIA Jetson、华为昇腾芯片)实现实时推理。

四、AI 视觉算法的技术挑战
尽管 AI 视觉算法已广泛落地,但仍面临以下关键挑战:
小样本学习(Few-Shot Learning):传统算法需大量标注数据,而现实中很多场景(如罕见病医疗影像)数据稀缺,如何用少量数据训练高精度模型是核心难题。
复杂场景鲁棒性:在光照变化(如夜晚、逆光)、遮挡(如行人被树木遮挡)、模糊(如运动模糊)场景下,算法精度易下降。
实时性与效率平衡:自动驾驶、安防监控等场景需 “毫秒级” 响应,但高精度模型(如 Mask R-CNN)计算量大,如何在精度与速度间平衡是关键。
伦理与隐私问题:人脸检测、行为分析等应用可能涉及用户隐私泄露,需解决 “算法公平性”(如避免种族、性别歧视)和隐私保护问题。
五、未来发展趋势
多模态融合:结合视觉(图像 / 视频)、文本、语音数据,提升算法理解能力(如 “根据文本描述 + 参考图像生成新图像”)。
轻量化模型:通过模型压缩(剪枝、量化)、知识蒸馏技术,在移动端、边缘设备(如摄像头)部署高精度算法。
自监督学习(Self-Supervised Learning):无需人工标注,通过 “图像补全”“对比学习” 等方式让模型自动学习特征,降低数据依赖。
可解释性 AI(XAI):目前深度学习模型被称为 “黑箱”,未来需提升算法可解释性(如 “为什么模型判断这是癌细胞”),尤其在医疗、司法等关键领域。
总之,AI 视觉算法是 “让机器拥有视觉感知能力” 的核心技术,其发展不仅推动了各行业的智能化升级,也在不断逼近人类视觉的理解能力,未来将在更多复杂场景中发挥关键作用。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















