
16 TOPS 与 8 TOPS 的性能差异在不同应用场景中呈现显著分化,这种差距不仅体现在算力数值上,更与硬件架构、软件优化和任务特性深度耦合。以下结合具体场景与技术细节展开分析:

一、自动驾驶:从辅助到高阶的算力鸿沟
L2 + 辅助驾驶(8 TOPS 适用)
典型任务:车道保持、交通标志识别、AEB 自动紧急制动。
性能表现:地平线征程 3 芯片的 5 TOPS 算力可支持 1080P 摄像头的实时视觉分析,处理 YOLOv5s 模型时帧率约为 15 FPS。但在复杂场景(如多车道变道 + 逆光)下,算力利用率接近极限,可能出现 50ms 以上延迟。
瓶颈分析:无法同时处理激光雷达点云与多传感器融合,如特斯拉 HW3.0 在 8 TOPS 算力下仅能支持基础 FSD 功能,遇到施工路段需降级为 L2。
L4 级自动驾驶(16 TOPS 起步)
典型任务:BEV 感知、多目标追踪、决策规划。
性能表现:地平线征程 6P 的 560 TOPS 算力(稀疏模式)可同时处理 12 路摄像头 + 4 激光雷达数据,BEV-Transformer 模型推理延迟≤10ms,支持城市 NOA 功能。若算力减半至 16 TOPS,需牺牲传感器数量(如仅用 8 路摄像头)或降低模型复杂度(如使用轻量版 YOLOv8n),导致目标检测距离缩短 30%。
技术突破:征程 6 的第三代 BPU 纳什架构通过动态资源分配,将 Transformer 模型计算效率提升至传统架构的 3 倍,使 16 TOPS 算力在特定场景下等效于 48 TOPS。
二、医疗影像:精度与效率的双重博弈
基础筛查(8 TOPS 可行)
典型任务:X 光胸片肺结节初筛、常规超声检查。
性能表现:华为昇腾 310 在 8 TOPS 算力下处理 CheXNet 模型,单张胸片分析时间约 200ms,准确率 94.3%。但遇到 3D CT 影像时,需将数据分块处理,总耗时超过 1 分钟,无法满足急诊需求。
量化优化:通过 INT8 量化可将 ResNet-50 模型从 16 TOPS 需求降至 8 TOPS,但精度损失约 1.5%,可能导致 5% 的微小结节漏检。
精准诊断(16 TOPS 必要)
典型任务:3D CT 肺结节良恶性判断、MRI 脑肿瘤分割。
性能表现:昇腾 310B 的 16 TOPS 算力结合动态精度补偿技术,处理 3D U-Net 模型时延迟≤3 秒,准确率 97.3%,满足临床标准。若使用 8 TOPS 设备,需将模型压缩至 MobileNet 级别,导致大肿瘤分割误差增加 2mm,影响手术规划。
实际案例:某县医院引入昇腾 AI 一体机后,CT 影像分析时间从 15 分钟缩短至 3 分钟,年误诊率下降 60%。
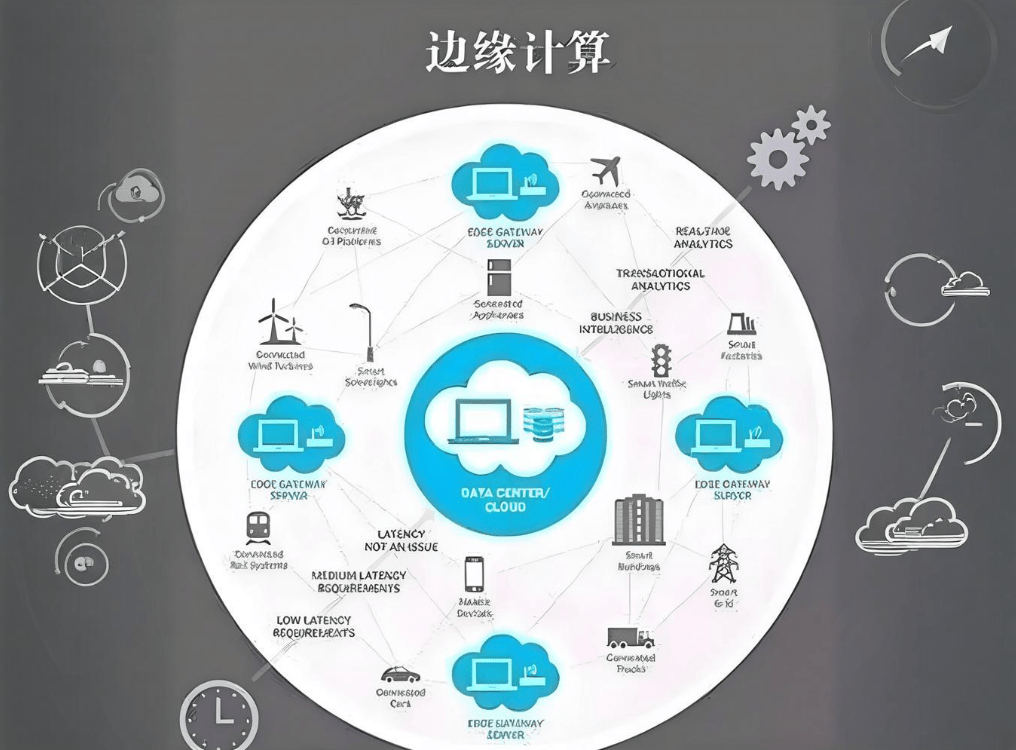
三、边缘计算:并发处理与能效的权衡
轻量级边缘节点(8 TOPS 够用)
典型任务:单路 1080P 视频分析、环境传感器数据融合。
性能表现:算能 BM1684X 的 8 TOPS 算力可同时运行 4 个独立视觉任务(如车牌识别 + 行为分析),总延迟≤50ms。但在工厂产线中,若需新增 OCR 识别功能,需动态关闭部分任务以释放算力。
能效优势:8 TOPS 设备功耗普遍低于 10W,如瑞芯微 RK3588 在 6 TOPS 算力下仅需 5W 供电,适合太阳能或电池驱动场景。
多模态边缘服务器(16 TOPS 必需)
典型任务:16 路 1080P 视频实时分析、多模型并发推理。
性能表现:XM-AIBOX-16 的 17.6 TOPS 算力可同时处理 16 路视频流,每路支持 3 个 AI 任务(如人脸识别 + 缺陷检测 + 计数),总吞吐量达 48 路任务,延迟≤200ms。若算力减半,需减少视频路数至 8 路,或降低单路任务数量,导致监控覆盖范围缩水 50%。
扩展性差异:16 TOPS 设备可通过动态资源调度(如昇腾 310B 的 CANN 平台)实现任务优先级管理,而 8 TOPS 设备通常缺乏此类功能,高负载下易出现任务队列积压。

四、工业质检:实时性与精度的硬约束
低速产线(8 TOPS 满足)
典型场景:家电外观检测、食品包装完整性检查。
性能表现:搭载 BM1684X 的边缘盒子在 8 TOPS 算力下,处理 2048×1024 分辨率图像时帧率达 15 FPS,可检测 0.1mm 级划痕,漏检率≤0.5%。但在产线速度提升至 2m/s 时,帧率需同步提升至 25 FPS,此时 8 TOPS 算力利用率超 90%,难以应对突发峰值负载。
高速产线(16 TOPS 关键)
典型场景:半导体晶圆检测、汽车零部件高精度测量。
性能表现:昇腾 310B 的 16 TOPS 算力结合动态 Patch 采样技术,处理 5120×2160 分辨率图像时帧率达 24 FPS,检测精度 ±1μm,满足 3C 产品微米级缺陷检测需求。若算力不足,需降低分辨率至 2K,导致微小裂纹漏检率上升至 3%。
成本对比:某汽车工厂引入 16 TOPS 质检系统后,年损失减少 100 万元,而 8 TOPS 方案因漏检导致的售后成本年均超 50 万元。
五、能效与场景适配的深层逻辑
能效比鸿沟
边缘场景:昇腾 310 在 8 TOPS 算力下功耗 8W,能效比 1 TOPS/W;昇腾 310B 在 16 TOPS 时功耗 15W,能效比 1.07 TOPS/W,提升仅 7%。这意味着翻倍算力需增加 87.5% 功耗,需在续航与性能间权衡。
数据中心:英伟达 H100 在 1979 TOPS(FP8)算力下功耗 700W,能效比 2.83 TOPS/W;昇腾 910B 在 256 TOPS(INT8)时功耗 315W,能效比 0.81 TOPS/W。高算力芯片在能效上的优势仅在大规模部署时显现。
架构级优化的影响
专用加速单元:地平线征程 6 的 BPU 纳什架构通过动态资源分配,使 16 TOPS 算力在 Transformer 模型上的实际吞吐量达 28 TOPS,等效于传统架构的 35 TOPS。
稀疏计算支持:昇腾 310B 的硬件级稀疏计算可跳过 50% 无效权重,使 16 TOPS 算力在 YOLOv8 模型上的实际帧率提升至 120 FPS,而 8 TOPS 设备仅能达到 60 FPS。

六、选型决策的关键维度
任务复杂度
若需处理多模态数据(如激光雷达 + 摄像头 + 毫米波雷达)或千亿参数模型(如 BEV-Transformer),16 TOPS 是底线选择。
单模态轻量任务(如语音唤醒 + 基础视觉)可优先考虑 8 TOPS 设备以控制成本。
实时性要求
工业质检(≤200ms)、自动驾驶(≤30ms)等强实时场景需 16 TOPS 提供冗余算力,避免因模型更新或负载波动导致延迟超标。
智能家居(≤1s)、环境监测(≤5s)等弱实时场景可接受 8 TOPS 的性能上限。
长期扩展性
选择支持混合精度(INT8/FP16)和动态量化的芯片(如昇腾 310B),可在 8 TOPS 算力下兼容 FP16 模型,为未来算法升级预留空间。
优先考虑开放生态(如 CUDA、CANN)的设备,以便迁移现有模型并利用社区优化成果,最大化算力利用率。
总结
16 TOPS 与 8 TOPS 的性能差异本质上是场景需求与算力供给的匹配度问题。在强实时、多模态、高精度场景中,16 TOPS 通过架构创新与算法优化建立不可替代的优势;而在轻量、低延迟、能效敏感场景中,8 TOPS 凭借成本与功耗优势仍具竞争力。未来随着量化技术(如谷歌 AQT)和稀疏计算的普及,两者的实际差距可能进一步缩小,但硬件架构与生态壁垒仍将长期存在。企业需基于具体业务需求,在算力、能效、成本间找到最优平衡点。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















