
FP8 通过算力翻倍、显存 / 带宽减半、通信压缩三大核心机制,在支持混合精度与动态缩放的同时,实现大模型训练 1.3–2 倍加速,且精度损失可控。
一、FP8 基础:两种 8 位浮点格式
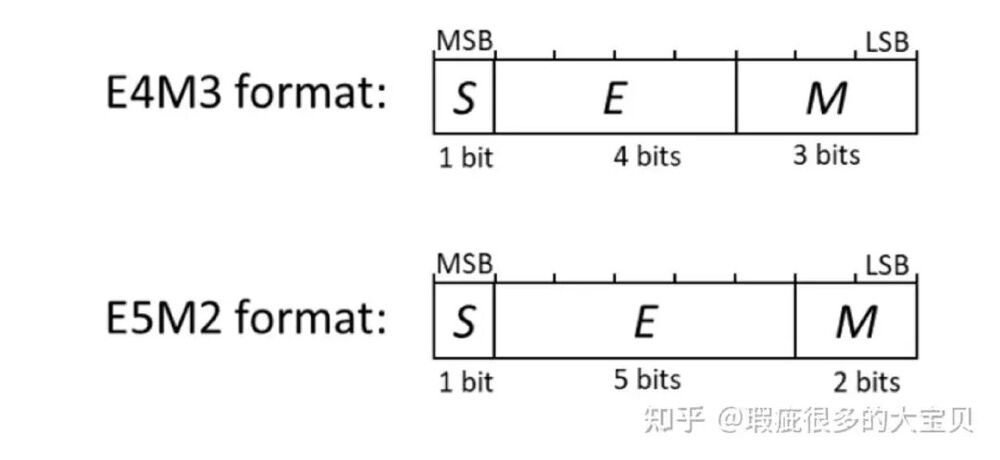
FP8 是 8 位浮点数,分两种格式适配训练不同阶段:
E4M3:1 符号位 + 4 指数位 + 3 尾数位,精度高、动态范围小,适合前向传播 / 激活值。
E5M2:1 符号位 + 5 指数位 + 2 尾数位,动态范围大、精度稍低,适合反向传播 / 梯度。
二、核心加速原理
1. 计算算力翻倍(硬件原生支持)
Tensor Core 峰值算力:FP8 是 BF16/FP16 的2 倍、TF32 的4 倍(H100/B200)。
计算密集型算子加速:矩阵乘法(GEMM)、注意力计算等核心操作直接用 FP8,单步时间显著缩短。
实测:H100 训练 Llama 3 405B,FP8 比 BF16 快1.53 倍;GPT-175B 训练提速75%。
2. 显存占用减半,缓解带宽瓶颈
数据体积:FP8(1 字节)vs BF16/FP16(2 字节),显存占用直接减半。
缓存利用率提升:更小张量让 GPU 缓存容纳更多数据,减少高延迟显存访问。
大模型收益:GPT-175B 显存占用减少39%,可训练更大模型或增大批次。
3. 通信带宽压缩,分布式训练提速
多机通信:张量并行 / 流水线并行中,FP8 传输数据量减半,通信时间减少约 50%。
节点间同步:梯度与优化器状态用 FP8,降低通信压力,提升分布式训练扩展性。
4. 混合精度 + 动态缩放,精度无损
计算用 FP8,存储用高精度:权重 / 优化器状态保持 BF16/FP32,仅计算时转 FP8,平衡速度与稳定性。
动态缩放(Per-Tensor/Block Scaling):每张量独立缩放,防止溢出;MXFP8 块级缩放进一步提升稳定性。
精度保持:主流模型(LLaMA/GPT)训练精度损失通常 \\<1%\\,可忽略。
三、FP8 vs 传统低精度
vs BF16/FP16:算力 ×2、显存 / 带宽 ÷2,加速比1.3–1.5 倍(模型越大越明显)。
vs INT8:FP8 为浮点数,动态范围自适应,无需固定缩放,避免 INT8 在 Transformer 中易溢出、精度损失大的问题。
四、典型工作流(以 Transformer Engine 为例)
1. 前向:权重→FP8(E4M3)→计算→输出→BF16。
2. 反向:梯度→FP8(E5M2)→计算→输出→BF16。
3. 更新:优化器状态保持 BF16/FP32,梯度 FP8→BF16 更新权重。
五、关键收益总结
训练速度:H100 上比 BF16 快1.3–1.5 倍,大模型(405B)可达1.53 倍。
显存节省:减少30–50%,支持更大批次 / 模型。
通信加速:分布式训练通信量减半,扩展性提升。
精度稳定:损失 \\<1%\\,主流模型无明显下降。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















