
车牌识别(License Plate Recognition, LPR)是一项融合计算机视觉、图像处理与模式识别的技术,其核心是通过多步骤算法 pipeline 实现 “从图像到车牌字符” 的精准转换。整个流程可拆解为图像预处理、车牌定位、字符分割、字符识别四大核心环节,每个环节对应不同的关键算法,且算法体系已从传统手工特征方法演进到深度学习主导的端到端方法。
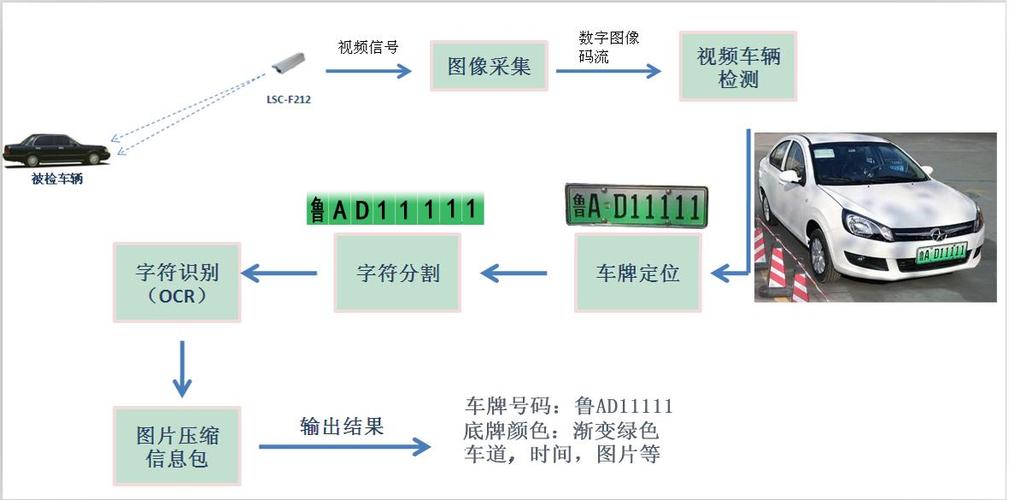
一、核心流程与对应算法
车牌识别的本质是 “逐步缩小识别范围、提升特征辨识度” 的过程,各环节的算法选择直接决定识别精度与鲁棒性(如抗光照、抗遮挡、抗变形能力)。
1. 第一步:图像预处理 —— 提升图像质量
原始图像常存在噪声、光照不均、倾斜等问题,预处理的目标是 “净化图像、突出车牌区域”,为后续步骤降低干扰。
常用算法包括:
灰度化:将彩色图像(RGB 空间)转换为灰度图像(单通道),减少计算量。核心是通过加权公式融合 RGB 通道(如 Gray = 0.299R + 0.587G + 0.114B),符合人眼对绿色敏感度最高的特性。
去噪滤波:消除图像中的随机噪声(如椒盐噪声、高斯噪声)。
高斯滤波:适合去除高斯噪声,通过高斯核(权重随距离中心衰减)平滑图像,保留整体轮廓。
中值滤波:适合去除椒盐噪声(孤立的亮 / 暗点),通过取邻域像素的中值替代中心像素,避免边缘模糊。
二值化:将灰度图像转换为黑白二值图像(仅 0 和 255),突出车牌字符(前景)与背景的对比。常用自适应阈值法(如 Otsu 算法),可自动根据图像灰度分布确定阈值,避免固定阈值在光照不均场景下的失效。
倾斜校正:修正车牌因拍摄角度导致的倾斜(如水平倾斜、垂直倾斜)。核心是通过霍夫变换(Hough Transform) 检测车牌的上下边缘(水平直线)或左右边缘(垂直直线),计算倾斜角度后通过仿射变换旋转校正。

2. 第二步:车牌定位 —— 从图像中找到车牌区域
车牌定位是 LPR 的核心难点之一,需从复杂背景(如车身、道路、树木)中精准提取车牌(通常为矩形区域,且有固定颜色特征)。算法分为传统手工特征法和深度学习目标检测法两类。
类别 | 核心算法 | 原理与优势 |
传统手工特征法 | 1. 边缘检测(Sobel/Canny 算子)2. 颜色空间分割(HSV/YCrCb)3. 纹理分析(LBP) | 1. 边缘检测:车牌字符与背景边缘差异大,通过 Sobel 算子检测水平边缘(突出字符笔画),Canny 算子提取连续边缘;2. 颜色分割:利用车牌固定配色(如国内蓝底白字、黄底黑字),在 HSV/YCrCb 空间中分割特定颜色区域,排除非车牌颜色干扰;3. 纹理分析:车牌字符排列密集且规则,通过 LBP(局部二值模式)提取纹理特征,筛选符合车牌纹理的区域。 |
深度学习检测法 | 1. YOLO(You Only Look Once)2. SSD(Single Shot MultiBox Detector)3. Faster R-CNN | 端到端直接检测车牌区域,无需手工设计特征:- YOLO/SSD:实时性强(10-100 FPS),适合车载、道闸等实时场景,通过 “网格划分 + 边界框回归” 定位车牌;- Faster R-CNN:精度更高(mAP>95%),适合静态高清图像,通过 “区域提议网络(RPN)” 生成候选框,再分类回归。 |
趋势:目前工业场景(如停车场、收费站)已普遍采用 YOLOv5/v8 或 SSD,兼顾实时性与精度,可应对遮挡(如贴纸)、变形(如弯曲车牌)等复杂场景。
3. 第三步:字符分割 —— 将车牌拆分为单个字符
车牌字符排列规则(如国内车牌为 “1 汉字 + 1 字母 + 5 字符”,共 7 个字符),字符分割需将定位后的车牌区域拆分为独立的字符图像(如 “京 A12345” 拆为 “京”“A”“1”“2”“3”“4”“5”),避免字符粘连干扰识别。
常用算法包括:
投影法(Projection Method):最经典的传统方法,分为水平投影和垂直投影。
水平投影:统计每一行的像素总和,找到字符的上下边界(投影值骤降的区域为字符间隙);
垂直投影:统计每一列的像素总和,找到字符的左右边界(投影值为 0 的列即为字符间的空白)。
优势:简单高效,适合无粘连、无倾斜的标准车牌;缺点:对字符粘连(如 “0” 与 “O”、“8” 与 “B”)或车牌污渍敏感。
连通区域分析(Connected Component Analysis):通过标记图像中 “相邻且像素值相同” 的区域(连通域),筛选出面积、宽高比符合单个字符特征的连通域(如汉字宽高比约 1:1,字母 / 数字宽高比约 3:5)。
深度学习分割法:对于复杂粘连场景,采用Mask R-CNN(实例分割) 或U-Net(语义分割),直接对车牌区域进行像素级分割,确定每个字符的掩码(Mask),再提取字符区域。

4. 第四步:字符识别 —— 识别单个字符内容
字符识别是 LPR 的最终目标,需判断分割后的字符是 “汉字、字母还是数字”(国内车牌字符集固定:31 个汉字 + 26 个大写字母 + 10 个数字,共 67 类)。算法同样分为传统方法和深度学习方法。
类别 | 核心算法 | 原理与适用场景 |
传统方法 | 1. 模板匹配(Template Matching)2. 特征提取 + 分类器(HOG+SVM、LBP+BP) | 1. 模板匹配:将待识别字符与预设的字符模板(如标准 “京”“A” 的像素模板)计算相似度(如归一化互相关),取最高相似度的模板作为结果;2. 特征提取 + 分类器:先通过 HOG(方向梯度直方图)或 LBP 提取字符的形状 / 纹理特征,再用 SVM(支持向量机)或 BP 神经网络(反向传播神经网络)分类;缺点:依赖手工特征设计,对字符变形、模糊鲁棒性差。 |
深度学习方法 | 1. CNN(卷积神经网络,如 LeNet、AlexNet)2. CRNN(卷积循环神经网络) | 1. CNN:端到端学习字符的视觉特征,通过卷积层提取局部特征、池化层降维、全连接层分类,适合清晰、无变形的字符;2. CRNN:专为 “序列字符” 设计(如车牌、身份证号),结合CNN(提取视觉特征)+ RNN/LSTM(处理字符序列依赖)+ CTC(连接时序分类,解决字符对齐问题),可直接输入整个车牌区域(无需分割),自动输出字符序列,对字符粘连、倾斜、模糊的鲁棒性远超传统方法;优势:工业场景主流方案,识别准确率>99%。 |
二、算法演进:从 “分步手工” 到 “端到端深度学习”
车牌识别算法的发展可分为三个阶段,核心趋势是 “减少人工干预、提升鲁棒性”:
传统阶段(2000-2015 年):依赖 “预处理→定位→分割→识别” 的分步手工算法,如边缘检测 + 投影法 + HOG+SVM,仅能应对光照均匀、无遮挡的理想场景,在复杂场景(如雨天、夜间、车牌污损)下准确率骤降。
深度学习分步阶段(2015-2018 年):各环节独立用深度学习优化,如 “YOLO 定位车牌 + CNN 识别字符”,精度显著提升,但仍需处理各步骤间的误差传递(如定位不准导致分割失败)。
端到端阶段(2018 年至今):用单一模型直接输入原始图像,输出车牌字符,无需拆分步骤。典型代表是CRNN+CTC或Transformer-based 模型(如 ViT),可自动学习从图像到字符序列的映射,极大简化流程,同时应对复杂场景的能力达到工业级要求。

三、关键影响因素与算法优化方向
实际应用中,LPR 的挑战主要来自环境干扰(光照、遮挡、雨雾)和车牌本身变异(变形、污损、个性化车牌),算法优化需围绕这些痛点:
抗光照:用Retinex 算法校正光照不均,或在训练时加入明暗增强的数据增强(如随机亮度、对比度调整);
抗遮挡:用注意力机制(如 SE 模块)让模型聚焦未遮挡区域,或在检测时采用 “部分车牌匹配” 策略;
抗变形:用仿射变换或弹性形变进行数据增强,提升模型对弯曲车牌的适应能力;
实时性:采用轻量化模型(如 YOLOv8-nano、MobileNet),在嵌入式设备(如边缘相机)上实现实时识别(≥30 FPS)。
总结
车牌识别的算法体系是 “多步骤协同、多技术融合” 的结果,核心逻辑是 “从图像净化到特征聚焦,再到序列识别”。目前,端到端的深度学习模型(如 CRNN、YOLO+CRNN) 已成为工业主流,其优势在于无需手工设计特征、能自动适应复杂场景,识别准确率在理想条件下可达 99.5% 以上,在交通管理、停车场收费、车辆溯源等场景中广泛应用。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















