
一、整体流程框架
反光衣识别本质是目标检测任务(识别图像/视频中反光衣的位置、数量、是否穿戴),完整训练流程如下:
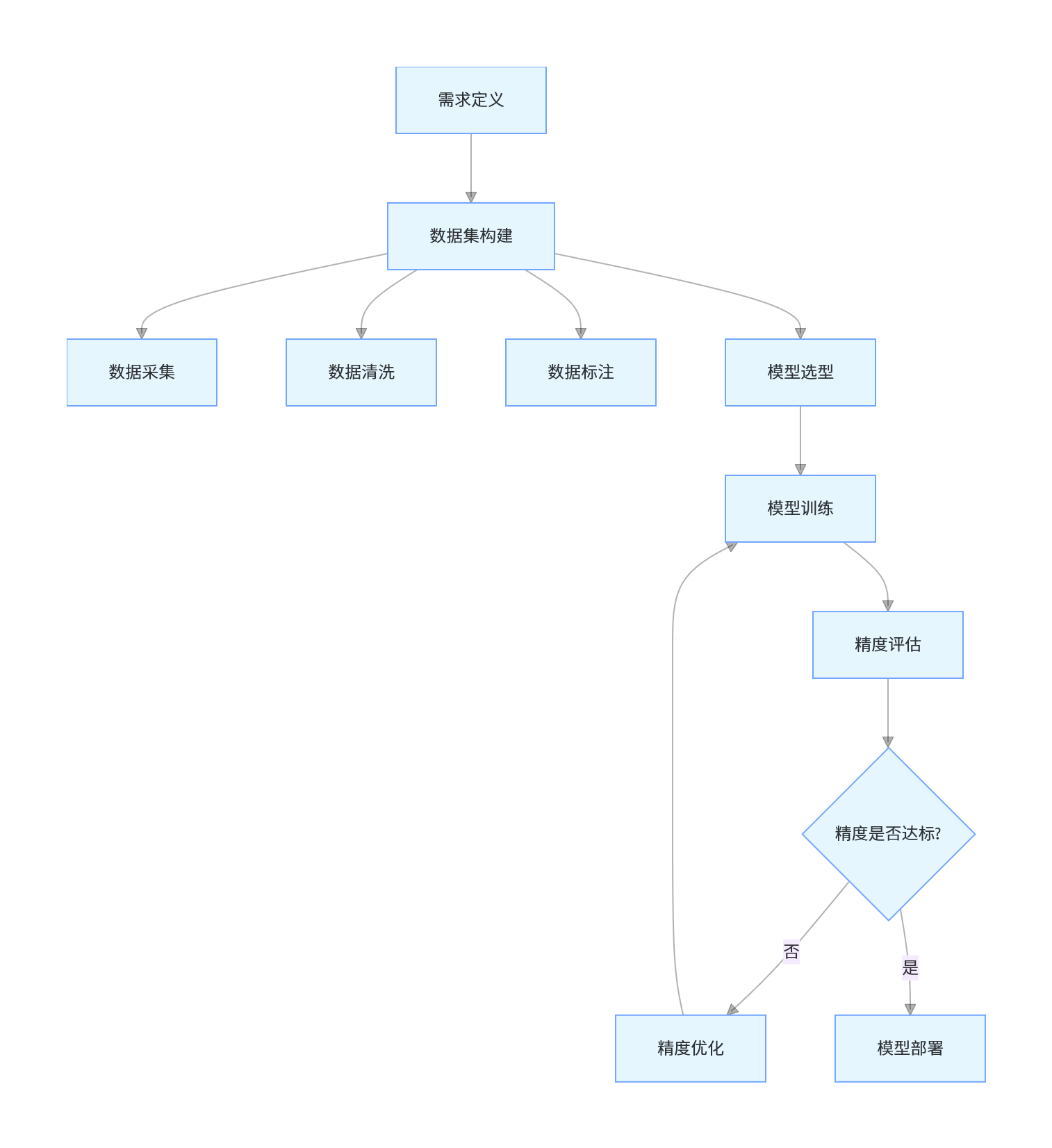
二、核心环节详解
1. 数据集构建(基础中的基础)
1.1 数据采集
目标:构建多样化、覆盖真实场景的数据集,避免过拟合。
采集场景(至少覆盖80%实际应用场景):
环境:白天/夜晚、晴天/雨天/雾天、室内/室外、强光/逆光/弱光;
角度:正面/侧面/背面、远/中/近景;
人物状态:站立/行走/弯腰、单人/多人、遮挡(部分被物体挡住)/无遮挡;
反光衣类型:不同颜色(红/黄/橙)、不同款式(背心式/连体式)、新旧程度。
数据来源:
自有采集:用摄像头拍摄工地/园区/交通场景的反光衣画面(图片≥5000张,视频抽帧≥10000帧);
公开数据集:补充工业安全数据集(如SafetyHelmetDataset扩展反光衣类别、COCO/YOLO数据集筛选反光衣相关数据);
数据增强生成:用SD/Stable Diffusion生成不同场景的反光衣合成数据(补充稀缺场景,如夜间逆光)。
数据格式:统一为JPG/PNG(图片)、MP4(视频),分辨率建议≥1080P(保证小目标可识别)。
1.2 数据清洗
过滤无效数据:模糊、过曝、反光衣占比<5%的图像;
去重:用哈希算法(如dHash)去除重复/高度相似的图像;
标准化:统一图像尺寸(如640×640)、色域(RGB),避免格式混乱。
1.3 数据标注(关键:标注质量决定模型下限)
标注工具:
轻量版:LabelImg(图片标注,新手友好)、LabelMe;
专业版:LabelStudio(支持图片/视频、多人协作)、VGG Image Annotator (VIA);
批量标注:借助半自动化工具(如SAM分割模型)先粗标,再人工修正。
标注规范(核心:统一标准,避免标注歧义):
1. 标注类别:仅定义reflective_vest(反光衣)一个主类别,避免细分导致样本分散;
2. 标注框(Bounding Box):紧贴反光衣边缘,不包含过多背景,也不遗漏反光衣区域;
3. 特殊情况:
部分遮挡:只要反光衣可见区域≥30%,仍需标注;
多人重叠:分别标注每个人的反光衣框,不合并;
无反光衣:无需标注(若需识别“未穿戴”,可新增no_reflective_vest类别);
4. 标注格式:导出为YOLO格式(txt文件,每行:类别ID 中心点x 中心点y 宽 高,均为归一化值),适配主流检测模型。
标注质检:
随机抽检:抽检10%-20%的标注数据,检查框的准确性、类别正确性;
一致性校验:多人标注同批数据,计算标注框的IOU(交并比),要求≥0.8,确保标注统一。
数据集划分:按7:2:1划分训练集(train)、验证集(val)、测试集(test),确保测试集包含所有场景类型,避免场景遗漏。
2. 模型选型与训练
2.1 模型选型(优先选轻量、高精度的目标检测模型)
模型 | 优势 | 适用场景 |
YOLOv8/YOLOv9 | 速度快、精度高、部署简单 | 实时检测(如监控视频) |
Faster R-CNN | 精度高、对小目标友好 | 静态图片高精度检测 |
SSD | 轻量化、适合低算力设备 | 边缘设备(如摄像头终端) |
首选YOLOv8:新手易上手,官方提供完整的训练/验证/部署工具链,且对反光衣这类中/小目标适配性好。
2.2 训练环境准备
硬件:GPU(显存≥8G,如NVIDIA RTX 3090/A10),CPU训练效率极低,不推荐;
软件:
基础环境:Python 3.8+、PyTorch 2.0+、CUDA 11.6+;
依赖库:ultralytics(YOLOv8官方库)、opencv-python、numpy、matplotlib。
2.3 核心训练代码(YOLOv8示例)
from ultralytics import YOLO
import os
# 1. 配置数据集路径(提前准备好data.yaml文件)
# data.yaml内容示例:
# train: ./dataset/train/images
# val: ./dataset/val/images
# test: ./dataset/test/images
# nc: 1 # 类别数
# names: ['reflective_vest'] # 类别名称
data_path = "dataset/data.yaml"
# 2. 加载预训练模型(迁移学习,提升训练效率和精度)
model = YOLO("yolov8s.pt") # s=小模型,m=中模型,l=大模型(精度更高但速度慢)
# 3. 模型训练
results = model.train(
data=data_path,
epochs=100, # 训练轮数(根据验证集精度调整,避免过拟合)
batch=16, # 批次大小(根据GPU显存调整,8G显存设为8,16G设为16)
imgsz=640, # 输入图像尺寸
lr0=0.01, # 初始学习率
lrf=0.01, # 最终学习率
weight_decay=0.0005, # 权重衰减,防止过拟合
augment=True, # 开启训练时的数据增强
patience=20, # 验证集精度20轮不提升则停止训练(早停)
save=True, # 保存最佳模型
val=True # 训练时验证
)
# 4. 模型评估(测试集)
metrics = model.val(data=data_path, split="test")
# 关键指标:mAP@0.5(IoU=0.5时的平均精度),目标≥0.95
print(f"测试集mAP@0.5: {metrics.box.map50:.4f}")
# 5. 保存模型(导出为ONNX/TensorRT等格式,用于部署)
model.export(format="onnx")
3. 精度提升技巧(核心:针对性解决精度问题)
3.1 先定位精度问题(明确优化方向)
查看混淆矩阵:确认是否有“漏检”(反光衣没识别)、“误检”(非反光衣识别为反光衣);
分析低精度样本:筛选测试集中预测错误的样本,归类问题类型:
1. 场景类:夜间/逆光/遮挡场景精度低;
2. 目标类:小目标(远距离反光衣)漏检;
3. 标注类:标注框不精准、类别错误。
3.2 针对性优化方案
问题类型 | 优化措施 |
数据集不足/场景单一 | 1. 补充对应场景的真实数据;2. 开启数据增强(翻转、缩放、亮度调整、马赛克);3. 合成数据补充 |
小目标漏检 | 1. 增大输入图像尺寸(如800×800);2. YOLO模型开启小目标检测头;3. 标注时细化小目标框 |
夜间/逆光识别差 | 1. 对图像做预处理(直方图均衡化、伽马校正);2. 单独标注夜间数据并增加训练权重 |
遮挡反光衣漏检 | 1. 补充遮挡场景的标注数据;2. 训练时增加遮挡类数据增强(随机遮挡) |
误检率高(把普通衣服识别为反光衣) | 1. 增加负样本(无反光衣的场景);2. 标注时严格区分类别;3. 降低学习率,增加训练轮数 |
过拟合(训练集精度高,测试集低) | 1. 增加权重衰减;2. 减少训练轮数/开启早停;3. 增加数据增强强度;4. 使用Dropout层 |
3.3 进阶优化
迁移学习优化:先用公开的反光衣/安全服数据集预训练,再用自有数据集微调;
模型融合:训练多个不同配置的YOLO模型(如v8s/v8m),融合预测结果,提升稳定性;
标注迭代:将模型预测错误的样本重新标注,加入训练集(迭代标注),逐步提升精度。

三、关键评估指标
反光衣识别的核心评估指标:
1. 精确率(Precision):识别为反光衣的样本中,真实是反光衣的比例(避免误检);
2. 召回率(Recall):所有真实反光衣中,被正确识别的比例(避免漏检);
3. mAP@0.5:综合精确率和召回率的核心指标,工业场景要求≥0.95;
4. 推理速度(FPS):实时检测要求≥30FPS(边缘设备≥15FPS)。
总结
1. 数据集是基础:需覆盖反光衣的全场景(环境/角度/状态),标注需严格统一,测试集要包含所有核心场景;
2. 训练选对工具:优先用YOLOv8/9,借助迁移学习快速收敛,通过早停避免过拟合;
3. 精度提升靠针对性优化:先定位漏检/误检的核心原因(场景/目标/标注),再通过补充数据、调整模型、迭代标注提升精度,核心指标聚焦mAP@0.5(目标≥0.95)。
按照这个流程,新手也能落地反光衣识别模型,核心是“数据先行、标注从严、优化精准”。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















