
使用实际场景模拟测试 AI 边缘计算盒子的性能,需结合目标应用场景构建真实业务流程,通过量化关键指标评估设备在复杂环境下的综合表现。以下是基于瑞芯微 RK3588 的典型场景测试方案,涵盖场景搭建、数据模拟、指标监控及优化策略:

• 硬件配置:
◦ 2x 4K 工业相机(模拟货架货物拍摄)
◦ 1x 二维码扫描器(模拟物流标签识别)
◦ RK3588 边缘计算盒子(接入仓储局域网)
• 软件环境:
◦ 操作系统:Ubuntu 20.04 + Linux 5.10 内核
◦ 算法框架:YOLOv8 物体检测 + ORB-SLAM3 定位导航
◦ 通信协议:MQTT 对接仓储管理系统(WMS)
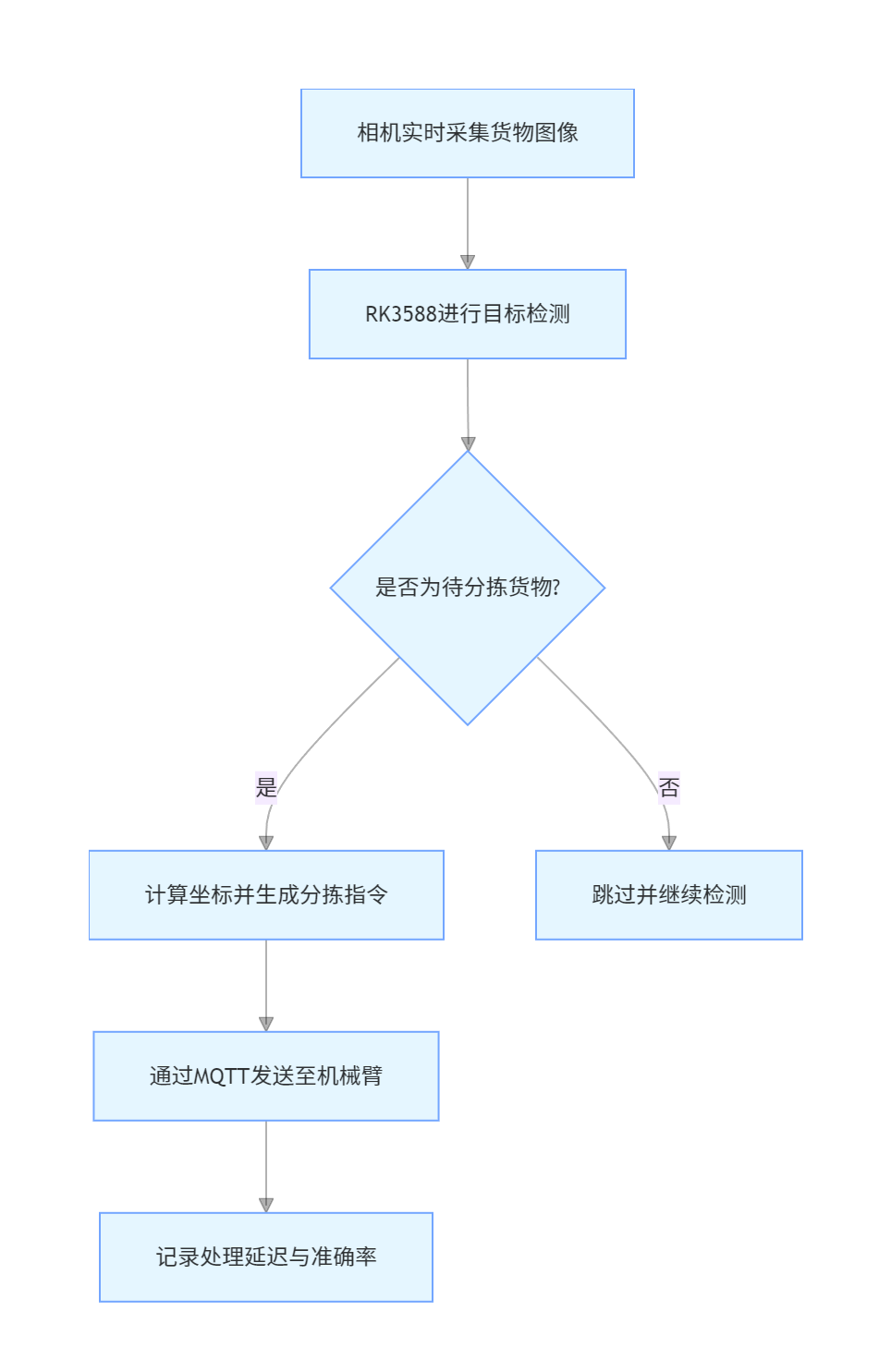
代码
graph TD
A[相机实时采集货物图像] --> B[RK3588进行目标检测]
B --> C{是否为待分拣货物?}
C --是--> D[计算坐标并生成分拣指令]
C --否--> E[跳过并继续检测]
D --> F[通过MQTT发送至机械臂]
F --> G[记录处理延迟与准确率]
3. 关键指标
• 实时性:货物检测延迟≤80ms(RK3588 通过 NPU 加速可优化至 50ms 内)
• 吞吐量:单相机处理帧率≥30FPS(多相机并发时需≥20FPS)
• 准确率:货物类别识别准确率≥99.2%(使用 INT8 量化模型时精度损失 < 0.5%)
• 抗干扰性:强光 / 阴影环境下检测误差≤3%(需启用 RK3588 的 ISP 降噪功能)
• 模拟 1000 件 / 小时的分拣量,同时运行 5 个检测模型(纸箱 / 塑料盒 / 金属件等多类别),监控:
# 实时查看NPU利用率
watch -n 1 "rknn_monitor -d"
# 监控网络传输延迟
• 硬件配置:
◦ 1x 线阵相机(模拟 PCB 板扫描)
◦ 光源控制器(可调亮度 / 色温)
◦ RK3588 盒子(通过 GigE 接口接相机)
• 算法模型:
◦ 缺陷检测:EfficientNet-B4 + 自定义异常检测模块
◦ 尺寸测量:Halcon 算子封装至 RKNN 模型
测试项 | 模拟条件 | 预期指标 |
高速流水线检测 | 传送带速度 1.5m/s(对应 500mm / 帧) | 检测漏检率 < 0.05%,误检率 < 0.1% |
多缺陷类型并发 | 同时存在划痕 / 缺件 / 焊点异常 | 处理延迟≤120ms(NPU 并行计算) |
温度波动适应性 | 环境温度 25℃~50℃(工业车间场景) | 检测精度波动 < 1.2%(需启用温控策略) |
• 利用 RK3588 的多 CORE-NPU 架构,将检测任务拆分为:
◦ CORE0-1:图像预处理(去噪 / 增强)
◦ NPU:特征提取与分类
◦ CORE2-7:后处理(坐标换算 / 结果整合)
• 测试脚本示例:
# 多线程任务分配 import rknn_api from concurrent.futures import ThreadPoolExecutor def preprocess(img):
# 使用OpenCV进行图像预处理
return cv2.GaussianBlur(img, (5,5), 0) def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img])
return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor:
for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
import rknn_api from concurrent.futures import ThreadPoolExecutor def preprocess(img):
# 使用OpenCV进行图像预处理
return cv2.GaussianBlur(img, (5,5), 0) def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img])
return postprocess(outputs)
with ThreadPoolExecutor(max_workers=4) as executor:
for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result())
results.append(future2.result())
from concurrent.futures import ThreadPoolExecutor def preprocess(img):
# 使用OpenCV进行图像预处理
return cv2.GaussianBlur(img, (5,5), 0) def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img])
return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
def preprocess(img):
# 使用OpenCV进行图像预处理
return cv2.GaussianBlur(img, (5,5), 0) def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img])
return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
# 使用OpenCV进行图像预处理
return cv2.GaussianBlur(img, (5,5), 0) def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img]) return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor:
for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
return cv2.GaussianBlur(img, (5,5), 0) def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img])
return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
def inference(model, img):
# RKNN推理
outputs = model.inference(inputs=[img])
return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
# RKNN推理
outputs = model.inference(inputs=[img]) return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
outputs = model.inference(inputs=[img]) return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream: future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
return postprocess(outputs) with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
with ThreadPoolExecutor(max_workers=4) as executor: for frame in video_stream: future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
for frame in video_stream:
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
future1 = executor.submit(preprocess, frame)
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
future2 = executor.submit(inference, rknn_model, future1.result()) results.append(future2.result())
results.append(future2.result())
三、智慧城市多摄像头监控场景
• 硬件配置:
◦ 4x 1080P 摄像头(模拟十字路口监控)
◦ 交换机(聚合 4 路视频流至盒子)
◦ GPS 模块(模拟车辆定位)
• 算法组合:
◦ 目标检测:YOLOv7-tiny(车辆 / 行人识别)
◦ 轨迹跟踪:DeepSORT(多目标跟踪)
◦ 交通事件分析:自定义规则引擎
• 多流并发处理: 4 路 1080P/30FPS 视频流同步处理,要求:
4 路 1080P/30FPS 视频流同步处理,要求:
◦ 整体延迟≤200ms(从摄像头采集到事件上报)
◦ 目标 ID 切换错误率 < 0.3%(考验 GPU+NPU 协同能力)
• 极端场景模拟:
◦ 暴雨 / 大雾天气:通过图像退化算法模拟(测试 ISP 抗噪能力)
◦ 高峰期车流(200 辆 / 分钟):测试吞吐量是否≥150 目标 / 秒
# 实时监控多任务资源占用 while true; do
# CPU核心利用率
cpu_usage=$(top -bn1 | grep "Cpu" | awk '{print $2+$4}')
# GPU负载
gpu_load=$(cat /sys/kernel/debug/mali/gpu0/load)
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
while true; do
# CPU核心利用率
cpu_usage=$(top -bn1 | grep "Cpu" | awk '{print $2+$4}')
# GPU负载
gpu_load=$(cat /sys/kernel/debug/mali/gpu0/load)
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
# CPU核心利用率
cpu_usage=$(top -bn1 | grep "Cpu" | awk '{print $2+$4}')
# GPU负载
gpu_load=$(cat /sys/kernel/debug/mali/gpu0/load)
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
cpu_usage=$(top -bn1 | grep "Cpu" | awk '{print $2+$4}')
# GPU负载
gpu_load=$(cat /sys/kernel/debug/mali/gpu0/load)
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
# GPU负载
gpu_load=$(cat /sys/kernel/debug/mali/gpu0/load)
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
gpu_load=$(cat /sys/kernel/debug/mali/gpu0/load)
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
# NPU利用率
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
npu_load=$(rknn_monitor -d | grep "NPU" | awk '{print $3}')
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
# 内存带宽
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
mem_bw=$(cat /sys/kernel/debug/bwmon/mem_bw_total) echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
echo "CPU: ${cpu_usage}%, GPU: ${gpu_load}%, NPU: ${npu_load}%, Mem: ${mem_bw}MB/s" sleep 1 done
sleep 1 done
done
• 硬件配置:
◦ DICOM 格式模拟器(生成 CT/MRI 影像)
◦ 触摸屏(模拟医生交互)
◦ RK3588 盒子(搭载医疗级散热模块)
• 算法模型:
◦ 肺部结节检测:3D UNet(量化为 INT8)
◦ 骨密度分析:ResNet-34 + 自定义回归头
• 影像处理速度:
◦ 单张 CT(512x512x300)重建时间≤400ms(利用 RK3588 的 GPU 浮点算力)
◦ 3D 分割推理时间≤1.2s(NPU 加速 3D 卷积)
• 精度要求:
◦ 结节检测召回率≥97%(对比云端模型差异 < 1.5%)
◦ 剂量估算误差 < 5%(需保持 FP16 精度部分算子)
• 连续运行 24 小时,每小时处理 100 例影像,监控:
◦ 机身温度≤45℃(医疗场景严格要求)
◦ 推理结果一致性:每 100 例随机抽取 5 例与云端对比,Dice 系数 > 0.98
1. 任务调度优化
◦ 使用 Linux cgroup 隔离关键任务:
# 创建AI任务组并限制CPU资源 sudo cgcreate -g cpu,memory:ai_task sudo cgset -r cpu.shares=2048 ai_task sudo cgexec -g cpu,memory:ai_task python3 inference.py
sudo cgcreate -g cpu,memory:ai_task sudo cgset -r cpu.shares=2048 ai_task sudo cgexec -g cpu,memory:ai_task python3 inference.py
sudo cgset -r cpu.shares=2048 ai_task sudo cgexec -g cpu,memory:ai_task python3 inference.py
sudo cgexec -g cpu,memory:ai_task python3 inference.py
◦ 利用 RK3588 的异构计算架构,将密集型计算分配至 NPU:
# RKNN-Toolkit2任务分配示例 from rknn.api import RKNN rknn = RKNN() rknn.load_rknn(model_path) rknn.init_runtime(target='rk3588', npu_mem_optimize=True)
# 启用NPU内存优化
from rknn.api import RKNN rknn = RKNN() rknn.load_rknn(model_path) rknn.init_runtime(target='rk3588', npu_mem_optimize=True)
# 启用NPU内存优化
rknn = RKNN() rknn.load_rknn(model_path) rknn.init_runtime(target='rk3588', npu_mem_optimize=True)
# 启用NPU内存优化
rknn.load_rknn(model_path) rknn.init_runtime(target='rk3588', npu_mem_optimize=True)
# 启用NPU内存优化
rknn.init_runtime(target='rk3588', npu_mem_optimize=True)
# 启用NPU内存优化
1. 实时性保障
◦ 启用 PREEMPT_RT 内核补丁(降低中断延迟至 100μs 内)
◦ 优化网络栈:
# 降低网络延迟 sudo sysctl -w net.core.default_qdisc=fq sudo sysctl -w net.ipv4.tcp_fastopen=3
sudo sysctl -w net.core.default_qdisc=fq sudo sysctl -w net.ipv4.tcp_fastopen=3
sudo sysctl -w net.ipv4.tcp_fastopen=3
1. 场景化性能调优参数
场景 | 优化参数 | RK3588 配置建议 |
智慧仓储 | NPU 频率提升至 1.6GHz | 通过 DTS 动态调整 clkin_npu 频率 |
医疗影像 | 保留 FP16 精度算子占比 30% | 在 RKNN 量化时设置 --keep-fp16 选项 |
多摄像头监控 | 启用 GPU 的视频编码硬件加速 | 使用 V4L2 驱动配置 H.265 编码 |
1. 建立场景化性能基线
◦ 对比云端处理方案的延迟优势:边缘端≤200ms vs 云端≥500ms(4G 网络)
◦ 能效比优势:RK3588 处理每帧功耗 1.2W vs 云端服务器每帧等效功耗 8W
1. 用户体验指标量化
◦ 仓储工人操作效率提升:分拣速度从 200 件 / 小时→350 件 / 小时
◦ 产线缺陷检测人力成本下降:从 3 人→1 人监控
1. 故障模拟与容灾测试
◦ 断网场景:本地缓存 1000 条数据,网络恢复后 30 秒内同步(测试存储与重传机制)
◦ 部分硬件故障:模拟 1 个 NPU 核心失效,系统自动切换至冗余核心,性能下降≤15%
通过上述场景化测试,可全面验证 AI 边缘计算盒子在真实业务中的可用性,同时针对 RK3588 的异构计算能力进行深度优化,确保设备在边缘环境下兼顾性能、功耗与稳定性。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















