
构建自主可控的 AI 算力生态闭环需要开源框架与国产芯片的深度协同,通过全栈技术创新和产业链整合实现从底层硬件到上层应用的自主化。以下是具体路径及实践:
一、硬件架构与开源框架的深度绑定
国产芯片厂商通过定制化架构设计和开源协议开放,实现与主流框架的无缝对接。例如:
华为昇腾 910B 搭载自研 NPU,通过开源 CANN 异构计算架构,兼容 CUDA 指令集并支持 PyTorch/TensorFlow 迁移。其 MatrixLink 高速总线技术将 384 颗昇腾 NPU 与 192 颗鲲鹏 CPU 对等互联,形成单卡推理吞吐量 2300 Tokens/s 的超级节点,较传统架构提升近 4 倍。
睿思芯科灵羽处理器 作为首款全自研 RISC-V 服务器芯片,通过 “一芯双核” 设计(32 个通用 CPU+8 个智算 LPU),原生支持 DeepSeek 等开源大模型推理。其开放的指令集架构吸引联想、长城等 50 余家合作伙伴,构建从芯片到整机的完整生态。
寒武纪 MLU590 依托 NeuWare 开发平台,支持 Caffe/PyTorch/TensorFlow 模型一键迁移,并通过 EasyDK/CNStream 工具链降低开发门槛。在某金融反欺诈场景中,寒武纪方案推理延迟较 GPU 方案降低 50%。

二、开源框架的国产芯片亲和性改造
主流框架通过代码重构和算子优化,实现对国产芯片的高效调度:
昇思 MindSpore 作为国产开源框架代表,通过八维混合分布式并行技术,使千亿参数模型训练效率提升 20%。其自动并行策略搜索功能将大模型调优周期从周级缩短至天级,并支持与 PyTorch 的无缝兼容(已兼容 1300 + 算子)。
清华赤兔引擎 针对国产芯片推出原生 FP8 支持,在 A800 集群部署 DeepSeek-R1-671B 时,GPU 使用量减少 50%,推理速度提升 3.15 倍。该引擎通过算子级优化(如 GeMM/MoE 指令级优化),确保模型精度无损。
PyTorch 生态适配 摩尔线程推出 Torch-MUSA v2.0,支持 PyTorch 2.5.0 及原生 FP8 计算,通过 MUSA 虚拟内存管理技术缓解显存碎片化问题。在某工业质检场景中,迁移后的模型推理速度达 NVIDIA A100 的 90%。

三、工具链与开发社区的协同进化
通过开源工具链降低开发门槛,吸引开发者共建生态:
编译器与调试工具 华为毕昇编译器针对昇腾芯片优化循环展开和内存访问,使 ResNet-50 训练速度提升 27%。寒武纪提供 CNRT 运行时库和 Nsight-like 调试工具,开发效率达 CUDA 生态的 76%。
开发者社区运营 昇思 MindSpore 社区已吸引 4 万 + 核心贡献者,通过 “智能基座” 项目覆盖 72 所高校,培养 40 万掌握 CANN 技术的学生。社区还开放算子共建平台,开发者可共享 20 余个高性能算子模板。
行业解决方案孵化 燧原科技联合美图、爱奇艺等企业,基于 S60 推理卡构建庆阳智算中心,4 天内完成近万张卡部署,支撑美颜相机 “AI 换装” 功能日均千万级并发。其 DeepSeek 一体机支持 1-32 卡灵活扩展,适配 Llama、通义千问等主流模型。
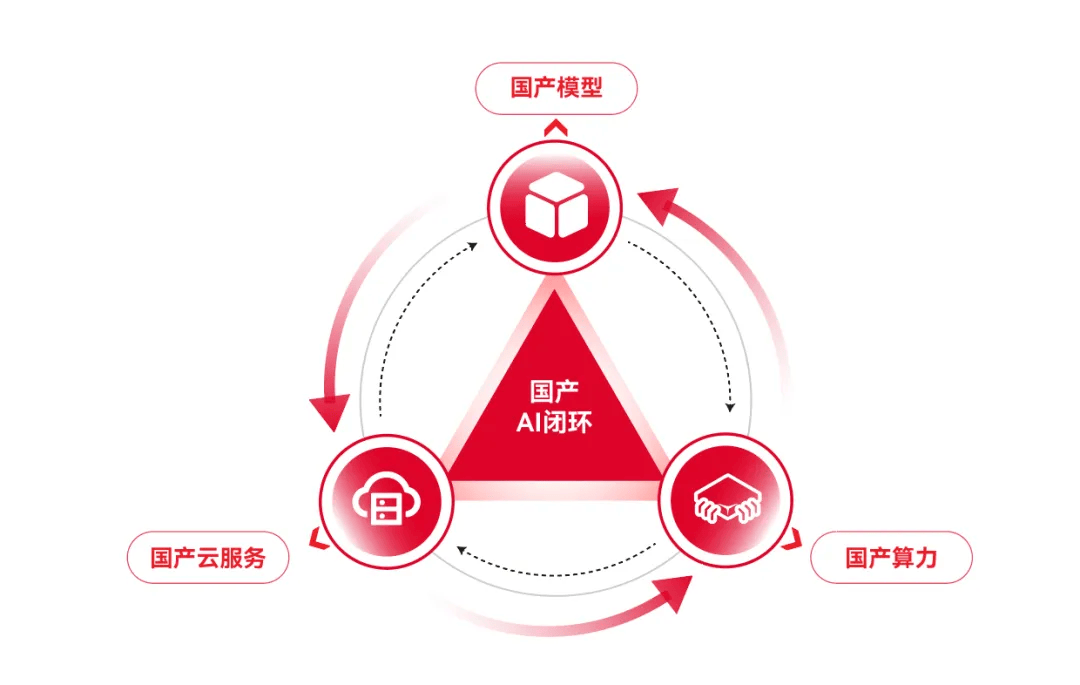
四、异构计算与统一编程模型突破
通过标准化接口实现跨芯片协同,打破生态孤岛:
统一编程框架 国防科技大学开发的 ParM 模型,支持 x86 / 英伟达 GPU / 鲲鹏 / 昇腾等多架构,性能达原始代码的 90% 以上。其队列式寄存器分配策略优化 RISC-V 数学函数性能,平均时钟周期从 144 降至 85。
跨平台算子库 华为 CANN 通过分层开放(算子层源码、编译层接口、驱动层调试),吸引西北工业大学团队开发 30 余个专用算子,构建抑郁症初筛系统并落地医院。
混合编程策略 天数智芯 BI-V100 采用 ROCm+oneAPI 双栈架构,通过 HIP 迁移 CUDA 代码(平均修改量 12%),同时利用 oneAPI 的 SYCL 模型优化跨设备调度。在某气象预测场景中,混合方案性能达纯 CUDA 的 92%。

五、行业落地与生态闭环验证
通过标杆项目验证技术可行性,形成 “需求 - 优化 - 反哺” 循环:
超大规模集群部署 哈尔滨智算中心实现 100% 国产芯片替代,采用 1.8 万张昇腾 910B 构建 6.93EFLOPS 算力集群,支撑中国移动九天千亿模型训练。其液冷系统和余热回收技术使 PUE 降至 1.1 以下。
垂直领域深度渗透 中国电信联合华为打造的昇腾超节点集群,在金融反欺诈场景中处理效率提升 3.8 倍,单节点支持百万级交易实时监测;在工业预测场景中,设备故障识别延迟从 300ms 降至 85ms。
RISC-V 的场景突破 中国电信研究院发布基于 RISC-V 的高性能工作站,搭载超睿 CPU 和希姆 AI 卡,支持 32B 参数的 DeepSeek 模型运行。其云原生虚拟化平台将硬件性能损失控制在 6% 以内,为边缘计算提供低成本方案。
六、政策支持与产业链协同
政府通过标准制定和资源投入加速生态建设:
算力网络规划 国家枢纽节点(如庆阳、芜湖)优先采用国产芯片集群,通过 “东数西算” 工程实现跨区域算力调度。哈尔滨智算中心获地方政府专项补贴,建设周期缩短 4 个月。
开源生态基金 华为设立 “昇腾开发者生态基金”,对基于 MindSpore 的行业解决方案给予最高 500 万元支持。智源研究院牵头的 FlagOpen 开源体系,吸引壁仞科技等企业参与大模型编译器(FlagIR)研发。
国际标准争夺 华为推动 CANN 加入 OpenHarmony 开源社区,计划在东南亚、中东建立 5 个技术创新中心,输出中国 AI 算力标准。
挑战与未来方向
工具链成熟度 国产芯片缺乏类似 CUDA NSight 的全生命周期开发套件,调试耗时增加 42%。需通过开源社区联合开发解决。
性能衰减问题 国产芯片实际算力利用率仅为理论值的 68-75%,需加强软硬件协同设计(如壁仞科技 BR104 集成 HIP/DPC++ 硬件加速单元)。
全球化适配 昇思 MindSpore 需进一步优化与 Hugging Face 等国际社区的兼容性,提升全球开发者参与度。
通过上述路径,国产算力生态已形成从 “可用” 到 “好用” 的跨越。未来需持续强化开源框架的主导权、芯片架构的原创性及产业链的韧性,最终实现 AI 算力的完全自主可控。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















