
一、硬件规格(先把参数说透)
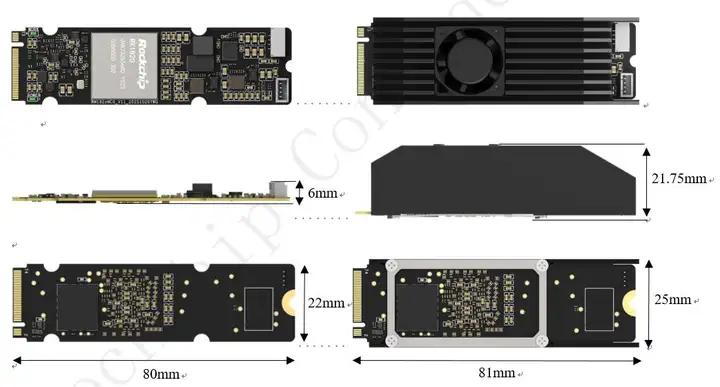
型号:RK1820MC0(M.2 Key M 2280)
NPU:20 TOPS @ INT8,支持 INT4/FP8/FP16 混合精度
片上内存:2.5GB 3D 堆叠 DRAM(关键:模型尽量卡内运行,减少 PCIe 开销)
接口:PCIe 2.0 x1(M.2 Key M),插 RK3588 核心板 / NAS / 工控机即用
功耗:约 5–7W,被动散热即可
二、实测平台与环境
主控:RK3588(6 TOPS 内置 NPU)
系统:Ubuntu 22.04 + RKNN3 SDK
对比:
仅 RK3588(6 TOPS)
RK3588 + RK1820(合计约 26 TOPS)
三、大语言模型(LLM)实测(最关心的)
1)Qwen 2.5 3B(INT8)
RK3588 单独:22–25 token/s
RK3588 + RK1820:65–70 token/s(≈ 2.8× 加速)
延迟:15–18ms/token,可流畅对话
2)Qwen 2.5 7B(INT8,模型约 5GB)
RK1820(2.5GB 片内):无法全载入,需 CPU 分载
实测:28–32 token/s,频繁 PCIe 交换,卡顿明显
结论:3B 舒适区,7B 勉强能用(RK1828 5GB 才能流畅 7B)
3)Llama 2 3B / Mistral 7B
Llama 2 3B:58–62 token/s
Mistral 7B:25–28 token/s(同 7B 瓶颈)
四、视觉模型 / 推理实测(工业 / 安防常用)
1)YOLOv8 系列(INT8)
YOLOv8n(640×640)
RK3588:35–40 FPS
RK1820:90–95 FPS(≈ 2.4×)
YOLOv8s(640×640)
RK1820:60–65 FPS
多流:4×1080P 同时检测 ≈ 30 FPS / 路,主控负载从 80% 降至 30%
2)Stable Diffusion(文生图,512×512)
RK3588:12–15 秒 / 张
RK1820:4–5 秒 / 张(≈ 3× 加速)
五、20 TOPS 到底 “够不够用”?
✅ 完全够用场景
端侧 3B 级 LLM 实时对话(Qwen、Llama 2、Mistral 小参数)
多路 1080P 视觉检测 / 分割(YOLOv8、Mask R-CNN)
工业质检、安防抓拍、车载环视(低延迟、高并发)
边缘 NAS / 工控机 AI 加速(M.2 插槽即插即用)
⚠️ 勉强 / 不够场景
7B 及以上 LLM 流畅交互(需 RK1828 5GB 或多卡)
4K 实时视频分析(单卡压力大,建议双卡)
大规模向量检索 / 多模态大模型(算力与内存均受限)
六、对比与选购建议
对比 RK1828:RK1820=20 TOPS+2.5GB;RK1828=20 TOPS+5GB,7B 模型优先 1828
对比 Hailo-8(26 TOPS):RK1820 性价比更高、生态更适配瑞芯微平台
一句话总结:20 TOPS 是端侧黄金算力 ——3B 模型拉满、视觉推理翻倍、功耗可控、M.2 通用
七、实测小结
理论 20 TOPS,实测有效算力约 18–19 TOPS(PCIe 有少量损耗)
3B LLM:65–70 token/s,流畅对话无压力
YOLOv8:90+ FPS,4 路 1080P 稳定运行
功耗 5–7W,被动散热即可,适合嵌入式 / 边缘场景
如果你是做 RK3588 核心板 + M.2 算力卡方案,RK1820MC0 是 3B 模型与视觉推理的高性价比首选;要跑 7B 直接上 RK1828。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















