
一、核心资讯概况
2026 年 6 月 15-16 日,国产 AI 芯片企业算苗科技(SUNMMIO)正式官宣:全自研 3D TokenPU 芯片顺利完成流片,是国内首款基于本土 3D 混合堆叠工艺落地的大模型专用推理芯片,实现从架构设计、晶圆制造到封测全流程国产化,打破海外在高端 3D 算力芯片领域的技术垄断。
二、核心架构与关键硬件参数
1. 底层架构:3D 混合堆叠(Hybrid Bonding)
区别传统 2D 平面、2.5D 中介层方案,采用晶圆级垂直堆叠 + TSV 硅通孔技术,将计算逻辑层与高密度存储层微米级紧密互连,大幅缩短数据传输路径,从物理层面解决 AI 行业长期存在的内存墙、带宽墙瓶颈。
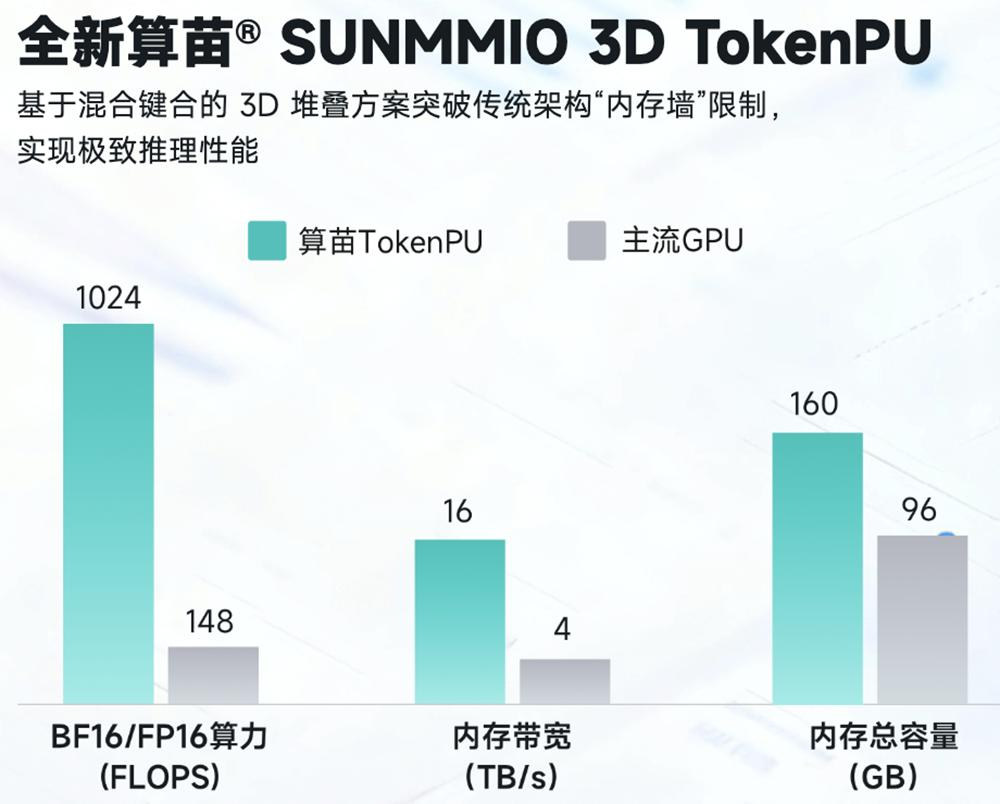
2. 核心硬件指标(对标主流高端 GPU)
参数 | 算苗 3D TokenPU | 主流高端 GPU | 提升幅度 |
BF16/FP16 算力 | 1024 TFLOPS | 148 TFLOPS | 约 6.9 倍 |
内存带宽 | 16 TB/s | 4 TB/s | 4 倍 |
片上存储容量 | 160 GB | 96 GB | 约 1.67 倍 |
16TB/s 超大内存带宽为核心亮点,大幅降低大模型推理时数据搬运功耗、缩短首字节响应时间(TTFT),同等功耗下 Token 推理吞吐量可达英伟达 H200 的1.26~2.19 倍。
三、三大核心技术创新(三位一体架构)
1. 物理层重构
混合键合 3D 堆叠,存储与计算垂直集成,互连延迟、传输能耗大幅下降,单位功耗 Token 产出显著提升,适配高并发对话、多模态生成场景。
2. 软硬协同优化
自研分布式全局访存架构,配套专用 AI 调度引擎,自动适配大模型、多模态模型算子,简化开发适配难度,兼顾通用性与专用推理能效。
3. 体系结构革新
针对大模型块状 Token 访问特征定制数据通路,带宽利用率远高于传统 GPU,显著降低智算中心单 Token 推理成本,支撑普惠算力落地。

四、国产化产业链支撑
算苗是国内首个具备万片级 3D IC 晶圆量产经验的团队,本次流片全链路依托国内供应链:团队拥有超 10000 片 3D 晶圆量产履历,3D 芯片累计商业化营收超 12 亿元;此前已完成累计近 10 亿元融资,资金全部用于国产 3D 算力芯片研发与量产落地。
五、落地应用场景
芯片专为云端大模型推理打造,覆盖全行业 AI 算力需求:
1. 通用大模型在线对话、智能客服、AI Agent;
2. 多模态生成:文生图、文生视频、语音大模型;
3. 政企智算中心、中小企业普惠算力集群;
4. 互联网高并发 AI 服务,降低算力部署成本与机房能耗。
六、行业意义
1. 技术代差追赶:国内 3D 堆叠 AI 推理芯片实现工程化流片落地,摆脱海外高端 3D 算力方案依赖;
2. 算力成本革新:超高带宽大幅缓解大模型推理带宽瓶颈,推动 AI 算力从稀缺资源转向普惠基础设施;
3. 国产算力生态完善:补齐本土高端推理芯片关键一环,为国产大模型、智算中心提供自主可控底层硬件底座。
七、后续进展
本次流片完成后,芯片将进入晶圆测试、封装验证阶段,后续将推出标准化算力板卡,面向云厂商、AI 企业开放适配,同步完善配套编译、调度软件生态。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















