
BM1684X 核心板依托32TOPS (INT8) 峰值算力与8 核 A53 处理器,通过算能 Sophon SDK 提供完整的算法支持与开发工具链,实现人脸检测 / 车牌识别等 AI 任务毫秒级响应,为边缘智能应用提供从模型开发到部署的全流程解决方案。

一、算法全景:覆盖视觉与多模态智能
1. 核心视觉算法(秒响应级)
算法类别 | 典型模型 | 性能表现 | 应用场景 |
人脸检测 | YOLOv8n-face、SCRFD、RetinaFace | 单帧检测 <3ms,支持 100 + 人脸同时检测 | 智慧安防、门禁考勤、刷脸支付 |
人脸比对 / 识别 | ArcFace、CosFace | 1:1 比对 >99.5%准确率,1:N 检索<10ms | 黑名单预警、VIP 识别、身份核验 |
车牌识别 (LPR) | LPRNet、YOLO-LPR | 单帧识别5-10ms,中文车牌准确率 ≥99% | 智慧交通、ETC、停车场管理 |
车辆分析 | YOLOv8、YOLOR | 车辆检测 <5ms,支持车型 / 颜色分类 | 交通流量统计、违章抓拍 |
人体分析 | YOLOv8-Pose、OpenPose | 18 关键点检测 <8ms,支持多人姿态识别 | 行为分析、安全合规检测 |
YOLOv5/6/7/8、SSD、Faster-RCNN | 小目标检测 <10ms,支持 200 + 类别 | 工业质检、智慧零售、周界防护 |
2. 扩展算法能力(全场景覆盖)
BM1684X 支持多类型 AI 算法,满足边缘智能多样化需求:
算法领域 | 代表能力 | 典型应用 |
图像分割 | Mask R-CNN、U-Net、DeepLabv3+ | 像素级语义 / 实例分割,<30ms单帧处理 |
图像增强 | Retinex、DNN 超分、去雾算法 | 低光 / 模糊图像实时增强,提升检测鲁棒性 |
OCR 识别 | CRNN、PP-OCRv4 | 文本检测 + 识别 <15ms,支持中英文混排 |
多目标跟踪 | SORT、DeepSORT | 目标 ID 持续追踪,<5ms每帧更新 |
轻量化 CNN | MobileNetV3、ShuffleNetV2 | 算力高效利用,功耗降低40%+ |
生成式 AI | Stable Diffusion Tiny、Phi-2 | 边缘端图像生成 / 小模型推理,<500ms响应 |
3. 算法优化特性
混合精度支持:INT4/INT8/FP16/BF16/FP32 全精度推理,在精度损失 <1%前提下性能提升3-5 倍 ;
专用指令加速:TPU 硬件加速 NMS、ROI Align、特征金字塔等视觉核心算子,降低 30%+后处理延迟;
多路并行处理:单核心板支持16-32 路高清视频流同步分析,解码 + 推理全流程边缘闭环;

二、开发工具链:Sophon SDK 全流程赋能
1. 核心工具链组件(Sophon SDK)
Sophon SDK 为 BM1684X 提供一站式开发环境,包含五大核心组件:
组件名称 | 核心功能 | 关键特性 |
TPU-MLIR 编译器 | 模型转换 + 优化 + 编译 | 支持 PyTorch/TensorFlow/ONNX 等主流框架,生成 BM1684X 专用bmodel |
TPU-NNTC 量化工具 | 模型量化(INT4/INT8) | 自动校准 + 量化,精度损失可控,性能提升3-10 倍 |
libsophon 运行时库 | TPU 推理加速 + 硬件抽象 | 提供 C++/Python API,支持多线程 / 多模型并行推理 |
bm-opencv 加速库 | 图像预处理加速 | 硬件加速 resize、crop、色彩空间转换,速度提升5 倍 + |
多媒体处理框架 | 视频编解码 + 流处理 | 支持 32 路 1080P@30fps 解码,硬件加速 JPEG 编码 |
2. 模型开发部署全流程
(1)模型转换流程(核心步骤)
原始模型(PyTorch/TensorFlow等)→ ONNX → MLIR → 量化(INT8/INT4)→ bmodel(板端专用);
关键步骤说明:
框架适配:直接支持 Caffe、PyTorch、TensorFlow、PaddlePaddle、Darknet、MXNet;其他框架通过 ONNX 转换兼容;
量化优化:支持PTQ (训练后量化)与QAT (量化感知训练),自动校准数据集生成,精度损失 <0.5%;
bmodel 生成:通过 model_deploy.py 编译为适配 BM1684X 的二进制模型,支持多核心并行推理;
(2)开发部署两种模式
部署模式 | 适用场景 | 开发流程 | 优势 |
SoC 模式 | 边缘独立设备(无 x86 主机) | 主机交叉编译 → 板端部署 → 本地运行 | 低功耗、无依赖、部署灵活 |
PCIe 模式 | 服务器 / 工控机扩展 | 主机直连开发 → 模型编译 → 本地推理 | 开发效率高、适合大规模部署 |
3. 核心工具使用示例
(1)模型量化命令(INT8 量化)
# 自动校准量化
tpu-nntc quantize \
--model model_fp32.umodel \
--calib_data calibration_dataset \
--output model_int8.umodel \
--chip bm1684x \
--precision int8
(2)bmodel 编译命令
# 生成BM1684X专用模型
model_deploy.py \
--mlir model_int8.mlir \
--chip bm1684x \
--output_dir output \
--name lprnet_bm1684x_int8
(3)Python 推理代码片段
import sophon.sail as sail
# 初始化设备
engine = sail.Engine("lprnet_bm1684x_int8.bmodel", 0, sail.IOMode.SYSO)
# 加载图像并预处理
img = cv2.imread("car_plate.jpg")
input_data = preprocess(img) # 归一化、resize等
# 推理执行(毫秒级)
output = engine.process("input", input_data)
# 后处理获取结果
plate_number = postprocess(output)
print(f"识别结果: {plate_number}")
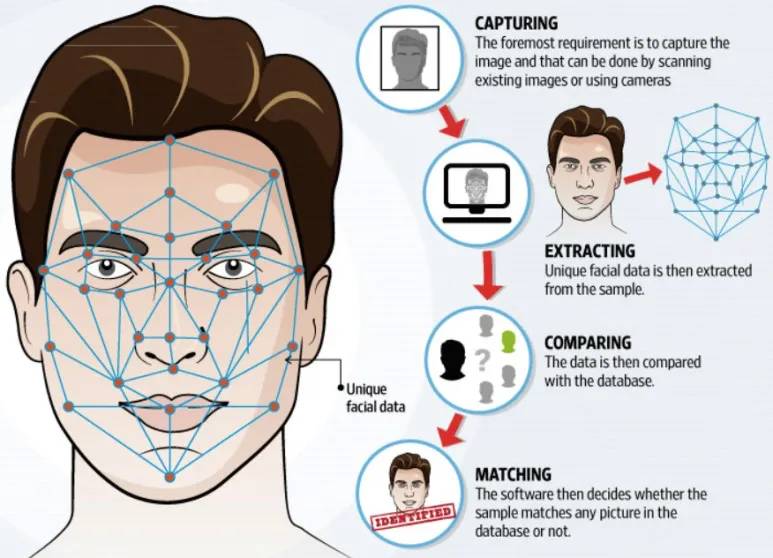
三、工具链优势与开发加速
1. 开发效率提升
一键部署:提供 Docker 镜像封装完整开发环境,5 分钟完成环境搭建;
丰富示例:SDK 内置 **100+** 预训练模型与参考代码(人脸 / 车牌 / 目标检测等);
多语言支持:C++/Python 双 API,适配不同开发团队技术栈;
自定义算子:支持 C++ 开发自定义 TPU 算子,适配特殊算法需求;
2. 性能优化技巧
精度选择:优先使用INT8 量化模型,在保持精度的同时获得最高性能;
批量推理:同一模型多帧批量处理,提升 TPU 利用率,降低单帧延迟;
硬件加速:使用 bm-opencv 替代标准 OpenCV,预处理速度提升5-10 倍;
多模型并行:利用 8 核 A53+TPU 协同,同时运行多个不同模型(如人脸 + 车牌 + 行为分析);
3. 调试与性能分析工具
bmrt_test:快速验证 bmodel 正确性与性能,输出单帧推理时间与算力利用率;
bm_perf:性能分析工具,定位推理瓶颈(预处理 / 推理 / 后处理各阶段耗时);
可视化工具:支持模型结构可视化、中间特征图查看,辅助算法优化;
四、典型开发案例:LPRNet 车牌识别部署
模型准备:获取预训练 LPRNet 模型(PyTorch/TensorFlow);
模型转换:转换为 ONNX → 生成 MLIR → INT8 量化(使用车牌数据集校准);
bmodel 编译:针对 BM1684X 生成专用模型,启用 4 核 TPU 并行;
应用开发:使用 Python/C++ API 开发视频流处理程序,集成车牌检测 + 识别;
部署运行:在 BM1684X 核心板上运行,实现7.8ms单帧识别,支持12 路1080P 视频流并行处理;
总结:从开发到部署的完整闭环
BM1684X 核心板通过丰富的算法支持与高效的开发工具链,为边缘智能应用提供了从原型到量产的全流程解决方案。无论是人脸检测、车牌识别等核心视觉任务,还是多模态智能应用,开发者都能借助 Sophon SDK 快速实现毫秒级响应的边缘 AI 部署,真正激活边缘场景的智能潜力。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















