
万物纵横 DA160S 搭载的SOPHON SDK 全栈开发工具链,是算能科技为 BM1688芯片(DA160S 核心 AI 处理器)量身打造的深度学习开发解决方案,与硬件形成16TOPS 算力 +≤10W 功耗 + 全栈工具链的黄金组合,大幅降低边缘 AI 应用开发门槛,这也是 DA160S 成为爆款的核心竞争力之一。

一、工具链整体架构:四层全栈设计,覆盖 AI 开发全流程
SOPHON SDK 采用四层架构,从底层芯片到上层应用,提供端到端开发支持,完美适配 DA160S 边缘计算场景:
层级 | 核心组件 | 功能定位 | 适配 DA160S 优势 |
底层驱动层 | bmlib、bmdriver、tpu-kernel | 芯片硬件抽象,提供基础运算接口 | 深度优化 BM1688 TPU,释放 16TOPS 算力,控制≤10W 功耗 |
核心加速层 | BMCV (计算机视觉库)、BMRuntime (推理运行时)、BMDecoder (视频解码) | 硬件加速核心,提供 AI 推理与多媒体处理能力 | 支持 16 路 1080P 视频实时分析,毫秒级响应工业场景 |
开发框架层 | sophon-sail (Python/C++ 接口)、sophon-mw (多媒体中间件) | 简化应用开发,封装底层复杂逻辑 | 提供 Python/C++ 双接口,降低开发门槛,适配边缘场景快速开发 |
应用工具层 | 模型编译器 (NNToolChain)、性能分析器、可视化工具 | 模型优化、调试与部署工具 | 支持 INT8 量化 (精度损失<1%),最大化能效比 |
二、核心组件深度解析:五大支柱支撑高效开发
1. NNToolChain:模型转换与量化的核心引擎
算能原创的深度学习模型编译工具链,是 DA160S 实现高效 AI 推理的关键:
框架兼容性:支持TensorFlow/PyTorch/Caffe/MxNet/PaddlePaddle等主流框架,通过 bmnet 系列工具(bmnett/bmnetp/bmnetc 等)实现一键转换,零代码跨平台迁移;
量化优化:内置INT8 量化工具,支持训练后量化 (PTQ) 与量化感知训练 (QAT),在 DA160S 上实现16TOPS@INT8 峰值算力,同时保证精度损失<1%;
模型压缩:自动进行算子融合、常量折叠等优化,模型体积减小 50%+,适配边缘设备存储与带宽限制;
2. sophon-sail:开发者友好的 Python/C++ 统一接口
SOPHON SDK 的核心应用开发接口,为 DA160S 提供极简开发体验:
双语言支持:同时提供 Python 与 C++ 接口,兼顾开发效率与运行性能;
全功能封装:对 BMRuntime、BMCV、BMDecoder 等底层库进行高度封装,一行代码即可实现模型推理;
示例丰富:内置 YOLOv5/YOLOv8/ResNet/SSD 等主流模型示例,DA160S 部署周期缩短 60%+;
多线程优化:适配 DA160S 多核心 CPU,支持多路视频流并行处理,充分发挥 16TOPS 算力;
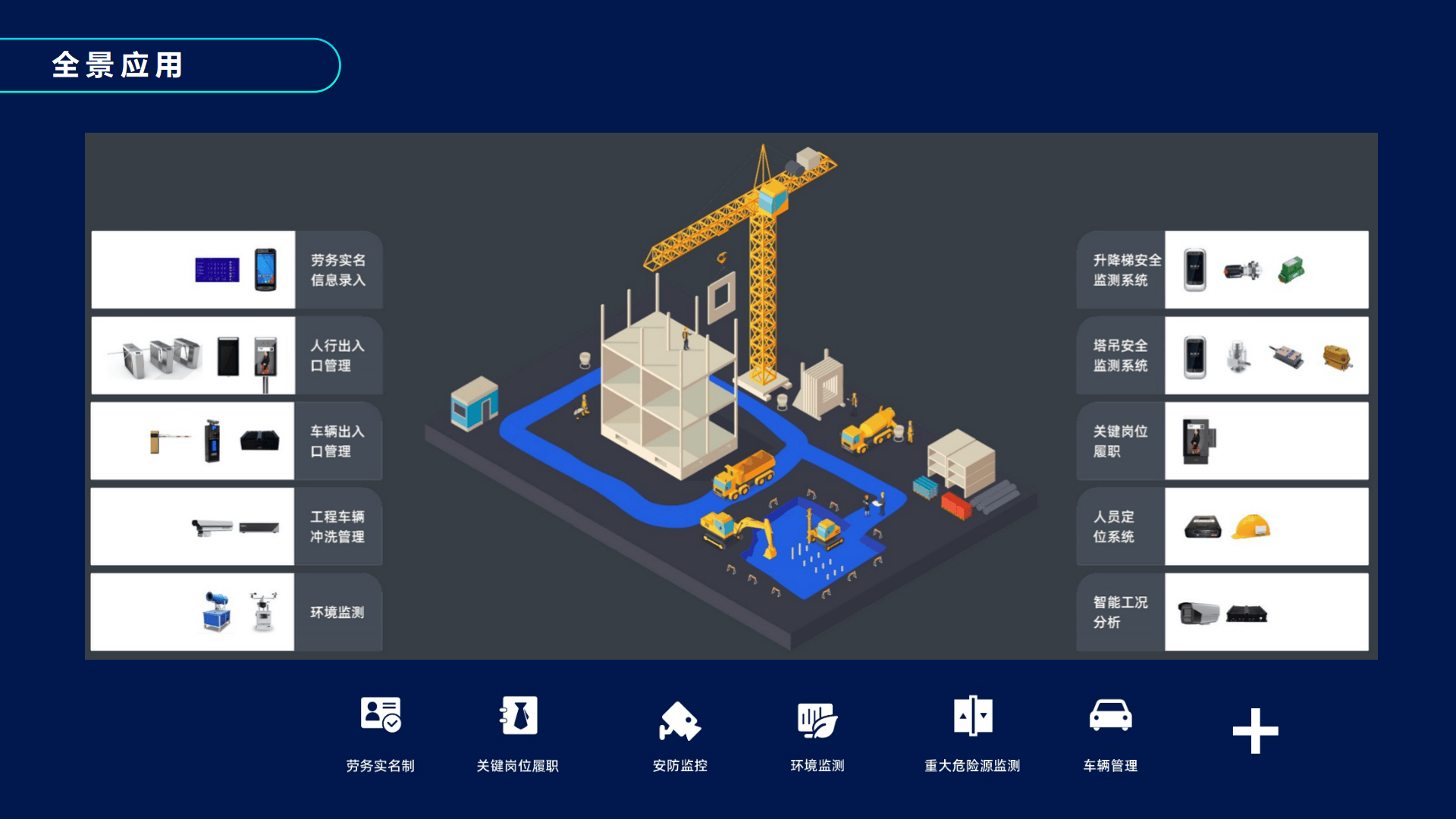
3. sophon-mw:多媒体处理中间件,赋能视频 AI 场景
专为边缘视频分析设计的多媒体处理库,解决 DA160S 视频接入与处理痛点:
视频接入:支持 RTSP/GB28181/ONVIF 等主流协议,适配 DA160S 在智慧工地、安防监控等场景的视频接入需求;
硬件加速:封装 BM-OpenCV、BM-FFmpeg,利用 DA160S 硬件编解码能力,支持 16 路 1080P 视频同时解码与分析;
图像处理:提供缩放、裁剪、色域转换等硬件加速操作,处理速度提升 10 倍 +,降低 CPU 占用;
4. BMCV:计算机视觉专用加速库,释放 TPU 视觉算力
针对 DA160S 的 BM1688 TPU 深度优化的计算机视觉库:
算子丰富:包含 200 + 计算机视觉专用算子,覆盖目标检测、图像分类、实例分割等场景;
异构计算:自动调度 CPU 与 TPU 协同工作,在≤10W 功耗下实现高效视觉处理;
低延迟设计:算子执行时间低至微秒级,保障 DA160S 在工业缺陷检测等场景的毫秒级响应;
5. 性能分析与调试工具:保障 DA160S 稳定高效运行
bmrt_test:模型推理性能测试工具,可精准评估 DA160S 上模型的吞吐量与延迟;
bmcv_perf:计算机视觉算子性能分析,优化算子调度策略;
sophon-dbg:远程调试工具,支持 DA160S 部署后在线调试,降低运维成本;
可视化工具:提供模型结构、数据流向可视化,便于开发者优化模型适配 DA160S 硬件;

三、DA160S 开发全流程:五步实现从模型到边缘部署
SOPHON SDK 为 DA160S 提供标准化开发流程,大幅降低边缘 AI 应用落地难度:
模型准备:在 PC 端训练模型(支持主流框架),或使用预训练模型;
模型转换与量化:通过 NNToolChain 将模型转换为 DA160S 支持的 BModel 格式,同时进行 INT8 量化优化;
# PyTorch模型转换示例
bmnetp --model=model.pth --shapes=input:1x3x640x640 --outdir=output
应用开发:使用 sophon-sail Python/C++ 接口编写推理代码,结合 sophon-mw 处理视频流;
# Python极简推理示例
from sophon.sail import Engine, Bmcv, Prefix
engine = Engine("model.bmodel") # 加载模型
bmcv = Bmcv(engine.handle()) # 初始化BMCV
img = bmcv.imread("input.jpg") # 读取图像
result = engine.process(img) # 模型推理
交叉编译与部署:使用 SDK 提供的交叉编译工具编译代码,部署到 DA160S;
性能调优与监控:通过性能分析工具优化代码,确保在≤10W 功耗下发挥 16TOPS 算力;
四、DA160S 专属优化:释放边缘算力的关键技术
SOPHON SDK 针对 DA160S 的16TOPS 算力 +≤10W 功耗特性进行了深度优化:
功耗与算力平衡:
自动根据负载调整 TPU 工作频率,在轻负载时降低功耗,满负载时释放 16TOPS 算力;
支持动态功耗管理 (DPM),确保长期运行功耗稳定≤10W;
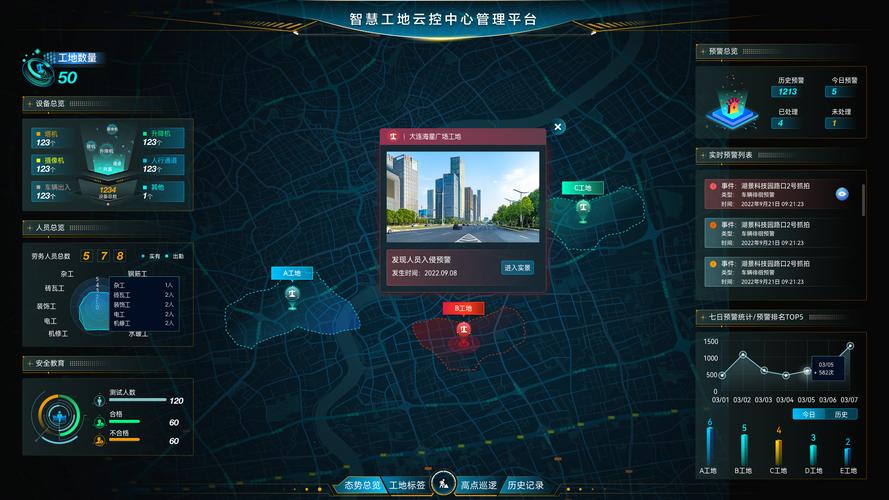
工业场景适配:
支持宽温 (-20℃~60℃) 环境下稳定运行,适配 DA160S 工业级设计;
提供断电保护与模型快速恢复机制,保障无人值守场景业务连续性;
多路视频并行优化:
优化内存调度,支持 16 路 1080P 视频流并行分析,每路处理延迟<100ms;
智能负载均衡,避免单路视频占用过多资源,确保多任务同时高效运行;
五、与传统开发工具链对比:DA160S 的核心优势
对比维度 | SOPHON SDK(DA160S) | 传统开发工具链 | 优势体现 |
开发效率 | 一站式工具链,部署周期缩短 60%+ | 需集成多个工具,配置复杂 | 降低边缘 AI 应用落地门槛,加速产品上市 |
硬件适配 | 深度优化 BM1688,释放 16TOPS 算力 | 通用适配,硬件性能发挥不足 | 最大化 DA160S 算力与功耗优势 |
推理性能 | INT8 量化 + 硬件加速,延迟<100ms | 软件模拟或通用加速,延迟高 | 满足工业实时性要求 |
功耗控制 | 动态功耗管理,稳定≤10W | 无针对性优化,功耗波动大 | 适配边缘设备供电限制 |
维护成本 | 远程调试 + 可视化监控 | 现场调试,维护复杂 | 降低 DA160S 部署后的运维成本 |
六、实际应用价值:赋能多行业边缘 AI 落地
SOPHON SDK 全栈工具链与 DA160S 硬件结合,已在多个行业展现出强大的应用价值:
智慧工地:快速部署安全帽检测、越界预警算法,本地实时告警,降低网络带宽 90%;
智能制造:通过 sophon-sail 快速开发工业缺陷检测应用,在 DA160S 上实现毫秒级响应,提升质检效率 50%+;
智慧零售:利用多路视频分析能力,实现客流统计与货架分析,数据本地处理保障用户隐私;
开发支持:万物纵横提供技术支持 + 二次开发服务,结合 SOPHON SDK 的丰富示例,帮助客户快速完成定制化开发;
总结:全栈工具链是 DA160S 火的核心密码
DA160S 的成功不仅在于16TOPS 算力 +≤10W 功耗的硬件优势,更在于 SOPHON SDK 全栈开发工具链解决了边缘 AI 开发的三大痛点:
开发难:提供一站式工具链,降低边缘 AI 开发门槛;
部署复杂:零代码模型转换,即插即用的部署体验;
性能与功耗平衡:深度优化硬件,在低功耗下释放高性能;
这种 "硬件性能 + 软件生态"的完美结合,让 DA160S 成为小型边缘算力盒子的标杆产品,真正实现" 万物为 DA160S" 的应用愿景。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















