
BM1688 核心板支持INT4/INT8/FP16/BF16/FP32 五种精度的混合精度计算,通过灵活的精度配置与量化优化,可在保证算法效果的同时实现算力与性能的最佳平衡。以下是详细解析:

一、支持的精度类型与算力对比
精度类型 | 峰值算力 | 数值范围 | 精度特点 | 典型应用场景 |
INT4 | 32 TOPS | -8~7 | 最低内存占用,最高计算效率,动态范围有限 | 大语言模型(LLM)推理、对精度要求不高的图像分类 |
INT8 | 16 TOPS | -128~127 | 平衡性能与精度的主流选择,内存占用减少 75% | 目标检测(YOLO 系列)、图像分割、OCR 等计算机视觉任务 |
FP16 | 4 TOPS | 5.96e-8~65504 | 半精度浮点,适合需要更高动态范围的场景 | 高精度图像处理、大模型特征提取 |
BF16 | 4 TOPS | 1.18e-38~3.4e38 | 脑浮点数,适合深度学习训练与推理 | 大模型推理、需要保持精度的复杂计算 |
FP32 | 0.5 TOPS | 1.18e-38~3.4e38 | 单精度浮点,最高精度,最大内存占用 | 模型训练、对精度要求极高的科学计算 |
二、混合精度计算与模型量化技术
BM1688 通过 SOPHON SDK 的 TPU-MLIR 编译器支持灵活的混合精度策略,可根据不同算子特性选择最优精度:
1. 量化方案
全量化:将模型所有算子转换为 INT4/INT8,获得最高性能;
部分量化:仅对计算密集型算子量化(如卷积、矩阵乘法),保留敏感层(如 BatchNorm、激活函数)为 FP16/BF16;
动态量化:根据输入数据分布动态调整量化参数,提升量化精度;
2. 量化优化技术
跨层权重均衡(WE):减少层间分布差异,提升量化精度;
偏置修正(BC):修正量化后偏置项的误差,降低精度损失;
校准优化:使用代表性数据集进行量化校准,减少量化误差;
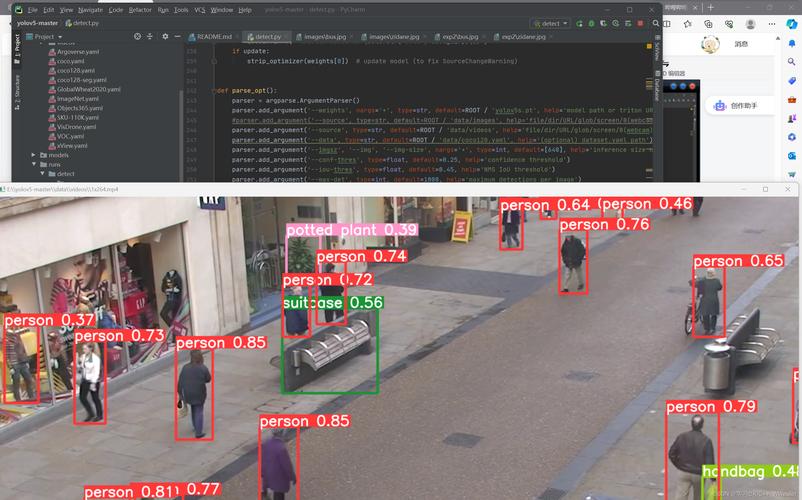
三、不同算法场景的精度配置建议
1. 计算机视觉算法
目标检测(YOLOv8):推荐INT8 量化,AP 精度损失通常 < 1%,推理速度提升 4-8 倍;
图像分类(ResNet50):INT8 量化后 Top-1 精度损失 < 0.5%,适合边缘端部署;
OCR(PP-OCR):采用 INT8+FP16 混合精度,文字识别准确率保持 99% 以上;
图像增强:建议使用 FP16 精度,确保图像处理质量;
2. 自然语言处理算法
大语言模型(LLM):
7B 参数模型:INT4 量化可在 BM1688 上实现实时推理,性能提升 8 倍,PPL(困惑度)增加 < 5%;
3B 以下模型:INT8 量化精度损失 < 2%,适合边缘端私有化部署;
文本分类:INT8 量化足以满足精度需求,推理速度提升显著;
3. 语音算法
语音识别:INT8 量化 + FP16 特征提取,WER(词错误率)增加 < 0.5%,适合实时语音转文字应用;

四、精度保持与调优方法
当量化模型出现精度下降时,可通过以下方法优化:
数据校准优化
使用与实际部署场景一致的校准数据集(建议≥1000 样本);
选择合适的校准算法(最小最大、熵校准、百分位校准);
量化参数调整
# 启用跨层权重均衡与偏置修正
model_transform.py --model_name resnet50 --model_def resnet50.onnx \
--input_shapes [[1,3,224,224]] --mean 0.485,0.456,0.406 \
--scale 0.229,0.224,0.225 --quantize INT8 --we --bc
混合精度策略
对精度敏感层(如检测头、分类器输出层)保留 FP16;
对大模型采用 INT4 权重 + FP16 激活的混合模式,平衡性能与精度;
五、实际部署精度表现
以典型模型为例,BM1688 上的量化精度表现如下:
模型 | 精度配置 | 精度指标 | 性能提升 |
YOLOv8n | INT8 量化 | mAP@0.5:0.95 > 37.5% | 比 FP32 快 16 倍 |
ResNet50 | INT8 量化 | Top-1 > 76.5% | 比 FP32 快 32 倍 |
PP-OCRv4 | INT8+FP16 混合 | 准确率 > 99.0% | 比 FP32 快 24 倍 |
LLaMa2-7B | INT4 量化 | PPL < 8.0 | 比 FP16 快 8 倍 |
CenterNet | INT8 量化 | AP@0.5:0.95 > 45% | 比 FP32 快 30 倍 |
六、总结与最佳实践建议
BM1688 的多精度支持为 AI 算法部署提供了灵活选择:
边缘计算优先选择 INT8:在大多数计算机视觉任务中,INT8 量化可实现精度与性能的最佳平衡;
大模型推理采用 INT4:在保证可接受精度的前提下,大幅提升推理速度与并发能力;
高精度需求场景:使用 FP16/BF16 混合精度,关键层保留 FP32;
量化调优步骤:先全 INT8 量化→评估精度→对敏感层调整为 FP16→重新量化优化;
通过合理的精度配置与量化优化,BM1688 可在边缘端高效部署各类 AI 算法,同时保持接近原始精度的算法效果。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















