
边缘检测和目标检测的常用算法因任务目标不同而有显著差异,前者以传统算子为主,后者则经历了从传统方法到深度学习方法的演变。以下分别介绍两者的典型算法:

一、边缘检测常用算法(以传统算子为主)
边缘检测的核心是通过计算像素灰度的梯度变化(或二阶变化)提取边缘,常用算法多基于数学算子,具体如下:
1. Roberts 算子
原理:基于一阶导数的 2x2 卷积核,通过计算对角线方向的像素差(如左上角与右下角、右上角与左下角)近似梯度,检测边缘。
公式:
水平对角线核: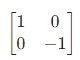 ,垂直对角线核:
,垂直对角线核: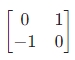 ,梯度大小为两核响应的平方和开根号。
,梯度大小为两核响应的平方和开根号。
特点:计算简单、速度快,但对噪声敏感(核尺寸小),边缘定位精度较低,适合噪声少的简单图像。
2. Prewitt 算子
原理:3x3 卷积核,通过计算水平和垂直方向的像素差近似梯度,对噪声的抑制能力优于 Roberts 算子(核尺寸更大,一定程度上平滑噪声)。
公式:
水平核: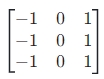 ,垂直核:
,垂直核: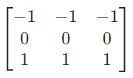 ,梯度大小为两方向响应的平方和开根号。
,梯度大小为两方向响应的平方和开根号。
特点:计算量适中,边缘提取较完整,但对边缘的方向敏感性不足,可能丢失细节。
3. Sobel 算子
原理:在 Prewitt 基础上优化,对卷积核赋予权重(中心像素权重更高),增强了对边缘的敏感性,同时进一步抑制噪声。
公式:
水平核: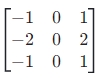 ,垂直核:
,垂直核: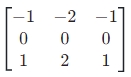 ,梯度大小计算同 Prewitt。
,梯度大小计算同 Prewitt。
特点:应用最广泛的传统算子之一,平衡了噪声抑制和边缘检测效果,适合多数场景(如工业检测、图像预处理)。
4. Laplacian 算子
原理:基于二阶导数,通过检测像素灰度的 “拐点”(二阶导数为 0 的位置)提取边缘,对灰度突变更敏感(如陡峭边缘)。
公式:常用 3x3 核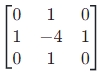 (或加入对角线的 8 邻域核),通过卷积计算二阶导数。
(或加入对角线的 8 邻域核),通过卷积计算二阶导数。
特点:对噪声非常敏感(二阶导数放大噪声),通常需先高斯滤波(形成 “高斯 - 拉普拉斯算子,LoG”);边缘定位精度高,但可能产生双边缘(对宽边缘效果差)。
5. Canny 边缘检测
原理:多步骤优化的 “流程化算法”,而非单一算子,核心步骤包括:
高斯滤波:去除噪声(避免噪声被误判为边缘);
计算梯度:用 Sobel 算子求梯度大小和方向;
非极大值抑制:只保留梯度方向上的局部最大值(细化边缘,避免宽边缘);
双阈值筛选:用高、低两个阈值区分强边缘(高阈值)和弱边缘(低阈值),仅保留与强边缘连通的弱边缘(去除孤立噪声)。
特点:目前性能最优的传统边缘检测算法,边缘连续、定位准确、抗噪声能力强,广泛用于医学影像(如 CT/MRI 轮廓提取)、自动驾驶(车道线初步检测)等场景。
其他边缘检测算法
Scharr 算子:Sobel 的改进版,核权重更精细(如水平核中心权重为 4),对高分辨率图像边缘检测更准确;
LOG 算子(Laplacian of Gaussian):先高斯滤波再拉普拉斯运算,减少噪声影响,但边缘可能模糊。

二、目标检测常用算法(传统方法→深度学习方法)
目标检测需要同时实现 “定位” 和 “分类”,算法从早期的手工特征 + 分类器,发展到现在的深度学习端到端模型。
(一)传统目标检测算法(2010 年前主流)
基于手工设计特征 + 分类器,依赖人工经验提取特征,精度和泛化能力有限。
1. Haar 特征 + AdaBoost 算法
原理:
Haar 特征:通过矩形区域内像素的灰度差描述目标(如人脸的 “眼睛暗、脸颊亮”);
AdaBoost:集成多个弱分类器(基于 Haar 特征)为强分类器,通过滑动窗口在图像中扫描,判断窗口是否为目标。
代表应用:Viola-Jones 人脸检测器(首个实时人脸检测算法)。
特点:速度快(适合实时场景),但特征单一,仅适用于简单目标(如人脸),对复杂背景或姿态变化鲁棒性差。
2. HOG 特征 + SVM 算法
原理:
HOG 特征(方向梯度直方图):将图像分块,统计每块中像素的梯度方向分布,捕捉目标的形状信息(如行人的轮廓);
SVM(支持向量机):对 HOG 特征分类,结合滑动窗口实现定位。
代表应用:Dalal-Triggs 行人检测器(经典行人检测方案)。
特点:比 Haar 特征更鲁棒,适合中等复杂度目标(如行人、车辆),但计算量大(特征维度高),速度较慢。
(二)深度学习目标检测算法(2010 年后主流)
基于神经网络自动学习特征,端到端训练,精度和泛化能力远超传统方法,分为两阶段(高精度)和单阶段(高速度)两类。
1. 两阶段目标检测算法(先 “候选区域” 再 “分类定位”)
(1)R-CNN(Region-CNN,2013)
原理:
用 “选择性搜索” 生成约 2000 个候选区域(可能包含目标的区域);
将每个候选区域缩放为固定尺寸,输入 CNN 提取特征;
用 SVM 分类,并用边界框回归修正位置。
特点:首次将 CNN 用于目标检测,精度远超传统方法,但步骤繁琐(候选区域独立处理)、训练慢、速度极慢(无法实时)。
(2)Fast R-CNN(2015)
改进点:
整图输入 CNN 提取特征,候选区域直接从特征图上裁剪(避免重复计算);
用 “ROI Pooling” 统一候选区域的特征尺寸;
分类和边界框回归用同一网络输出(多任务损失),端到端训练。
特点:速度比 R-CNN 快 10 倍,精度更高,但候选区域仍依赖 “选择性搜索”(耗时)。
(3)Faster R-CNN(2015)
改进点:
用 “RPN(Region Proposal Network)” 替代选择性搜索,在特征图上生成候选区域(与 CNN 共享特征,速度大幅提升);
RPN 同时预测候选区域的位置和 “前景 / 背景” 概率,实现端到端的候选区域生成。
特点:首个真正意义上的端到端两阶段模型,精度顶尖(COCO 数据集早期 SOTA),但速度仍较慢(每秒 5-10 帧),适合对精度要求高的场景(如医学影像分析)。

2. 单阶段目标检测算法(直接 “分类 + 定位”,无候选区域)
(1)YOLO(You Only Look Once,2016)
原理:
将图像划分为 S×S 网格,每个网格预测 B 个边界框和类别概率;
用一个 CNN 直接输出所有网格的检测结果(分类 + 定位),端到端训练。
特点:速度极快(YOLOv1 达 45 帧 / 秒),但小目标检测差(网格划分限制)、定位精度低于两阶段模型。
(2)SSD(Single Shot MultiBox Detector,2016)
原理:
在 CNN 的多个不同尺度特征图上预测目标(大特征图检测小目标,小特征图检测大目标);
每个特征图的每个位置预设多个不同比例的 “先验框”,预测框与先验框的偏移量和类别。
特点:速度与 YOLO 相当(59 帧 / 秒),小目标检测优于 YOLOv1,但对密集目标和复杂背景鲁棒性仍不足。
(3)YOLO 系列改进(YOLOv3-v8,2018-2023)
改进点:
多尺度特征融合(如 YOLOv3 的 FPN 结构,增强小目标检测);
更高效的网络 backbone(如 CSPNet);
动态锚框、损失函数优化(如 CIoU)等。
特点:YOLOv5/v8 实现了精度(接近两阶段)和速度(30-300 帧 / 秒)的平衡,成为工业界主流(如自动驾驶、监控)。
(4)RetinaNet(2017)
原理:
用 FPN 提取多尺度特征,类似 SSD;
引入 “Focal Loss” 解决单阶段模型中 “正负样本不平衡”(背景样本远多于目标样本)的问题,提升精度。
特点:单阶段模型中首次在精度上追平两阶段模型,成为后续单阶段算法的基础(如 FCOS)。
总结
边缘检测:以传统算子为主,Canny 因综合性能最优应用最广;
目标检测:深度学习主导,两阶段(如 Faster R-CNN)适合高精度场景,单阶段(如 YOLOv8)适合实时场景,传统方法仅在简单场景中偶尔使用。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















