
RK1828 是瑞芯微 RK182X 系列旗舰 AI 协处理器,依托RKNN3 全套工具链构建的完善软硬件生态,实现从视觉检测、传统 CNN、多模态 VLM 到大语言 LLM 的全品类开源算法兼容,是边缘端本地化大模型部署主流国产算力方案。
一、RKNN3 成熟完备生态体系(底层支撑)
RKNN3 SDK V1.0 专为 RK1820/RK1828 定制,提供训练→转换→量化→调试→部署全链路开发栈,打通开源模型迁移壁垒:
1. 全流程工具链
1. RKNN3-Toolkit(PC 端)
兼容 PyTorch、TensorFlow、Caffe、MXNet、ONNX 全球主流训练框架,一键模型转换;支持 W4A16/W8A8/FP16/INT4 多精度混合量化,内置精度校验、性能测速、算子调试工具,可直连开发板实时分析推理损耗。
2. RKNN3 Runtime(板端运行库)
提供 C/C++、Python 双 API,原生兼容 OpenAI 标准接口,rkllm3-server 开箱即用支持 Embedding、Function Call、mRoPE 大模型核心特性;支持多模型并行推理、传输与计算并行,高并发场景性能提升明显。
3. RKNN3 Model Zoo 开源模型库
Gitee/GitHub 开源 500 + 算法示例,覆盖视觉、LLM、多模态全品类;Hugging Face、ModelScope 开源模型可直接复用转换脚本,无需从零适配。
4. 硬件适配生态
接口:M.2 Key B-M、SODIMM、PCIe、USB3.0,即插即用,适配 RK3588/RK3576 全系主控、工控机、边缘盒子;
系统:Linux、Android 双系统全覆盖;
扩展:多卡并联算力堆叠,独立 NPU 推理不占用主控 CPU / 内存资源。
2. 生态配套优势
Rock-X 预置算法组件:人脸识别、目标检测、分割、OCR 成熟封装,大幅缩短开发周期;
完善驱动、调试工具 RKNN-SMI、官方技术文档、开发者社区持续更新模型适配补丁;
全国产软硬件闭环,适配工业、安防、机器人、车载、本地 AI 终端等量产落地场景。
二、RK1828 硬件基础:支撑全量级模型流畅运行
RK1828 是系列高配算力协处理器,硬件规格决定超大模型兼容能力:
1. 算力:峰值 20TOPS INT8 NPU,多核 RISC-V 辅助处理;
2. 内存:5GB 3D 堆叠高带宽 DRAM(对比 RK1820 仅 2.5GB);
3. 模型上限:原生支持0.5B~8B所有主流开源大模型,RK1820 上限仅 3B;
4. 计算精度:INT4/INT8/FP16 混合计算,轻量化量化后精度损失可控。
三、RK1828 全兼容主流开源大模型(LLM/VLM 多模态)
依托 RKNN3 深度算子优化,完整适配国内外主流开源大模型,实测推理低延迟、高 Token 生成速度:
1. 大语言 LLM 模型
通义千问系列:Qwen2.5(0.5B/1.5B/3B/7B)、Qwen3(0.6B/1.7B/4B/8B)
国产开源:GLM-Edge、MiniCPM、阶跃 Step-GUI-Edge、HY-MT 系列
海外开源:Llama3、Gemma、Youtu-LLM
配套 Embedding / 重排模型:Qwen3-Reranker、Qwen3-Embedding 全适配
实测性能参考
Qwen2.5-3B:Decode TPS 87+;
Qwen2.5-7B:首帧延迟 161ms,TPS 59;
Qwen3-8B 可稳定本地离线推理,满足交互场景实时性要求。
2. 视觉多模态 VLM 图文大模型
Qwen2.5-VL、Qwen3-VL、InternVL3/3.5、FastBVLM、CLIP、Qwen2.5-Omni 全模态音视语言模型;
RK1828 运行 Qwen2.5-VL-3B 可达 85.98 TPS,全模态 Omni-3B 解码 TPS 突破 102,可实现看图问答、视频理解、语音图文联动。
四、RK1828 全兼容主流开源视觉算法
传统计算机视觉 CNN / 检测 / 分割 / 跟踪模型原生适配,工业视觉、安防检测、机器人感知全覆盖:
1. 目标检测系列
YOLOv5/v6/v7/v8/v9、YOLO-NAS、RT-DETR;RK1828 跑 YOLOv5s 640 分辨率单帧推理≤31ms,多核心并发 FPS 超 210,满足实时监控需求。
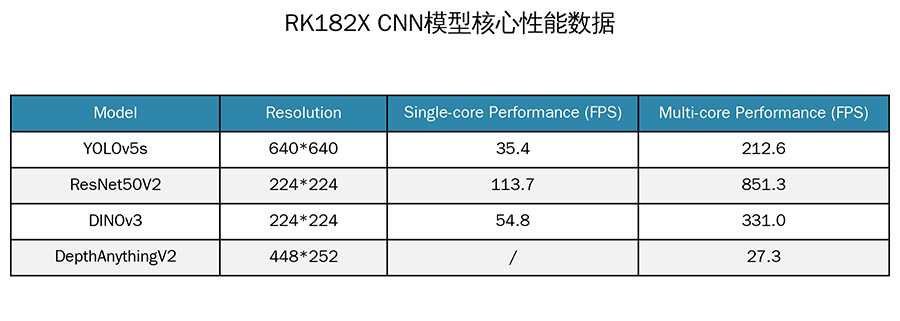
2. 图像分类 / 分割 / 感知
MobileNet、ResNet、EfficientNet、DINOv3、DepthAnythingV2、Mask R-CNN、U-Net;
支持深度估计、语义分割、实例分割、特征提取等工业视觉标准算法。
3. 轻量化 / 专用视觉算法
OCR、人脸识别、人体姿态、车道线检测、缺陷检测、图像增强、光流跟踪等,Rock-X 组件直接封装调用,开箱即用。
五、核心落地价值总结
1. 生态闭环无适配门槛:RKNN3 打通训练到部署,开源模型一键迁移,降低 AI 硬件开发成本;
2. 硬件上限更高:RK1828 超大 5GB 内存,唯一可流畅跑 8B 参数大模型的 RK182X 型号;
3. 视觉 + 大模型一体化:同一块算力卡同时承载实时视觉检测与本地大语言交互,适配机器人、智能座舱、边缘分析一体机;
4. 轻量化量产友好:M.2 标准接口、低功耗独立算力,无需更换主控即可为现有设备扩容 AI 能力,广泛用于本地离线隐私计算场景。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















