
视频异常侦测AI算法已实现效率提升100倍+的实测突破,核心是轻量预过滤+大模型精检的级联架构,在NVIDIA L40S上跑出57.68 FPS、151.79×加速,精度达97.2%。下面从实测数据、技术原理、落地场景展开说明。
一、实测核心数据(效率+精度双优)
1. 效率突破(100倍+)
Cerberus(2025):在L40S GPU上,从传统VLM的0.38 FPS提升至57.68 FPS,151.79×加速,单GPU可实时处理57路1080P视频。
自蒸馏MAE(CVPR 2024):极致轻量,推理速度1655 FPS,适合边缘端海量视频流。
帧间差异法:替代全帧重构,速度38.6 FPS,比SDMAE快26.6%,误报率更低。
2. 精度保障(SOTA级)
Cerberus:97.2%准确率,在Avenue、ShanghaiTech等4个数据集上持平顶尖VLM方法。
LAVIDA:零样本跨场景,UBnormal 76.45% AUC、UCF-Crime 82.18% AUC,无需真实异常数据。
EventVAD(北大/清华/京东):免训练、7B参数,UCF-Crime/XD-Violence上超越SOTA。
二、效率暴涨的技术原理
1. 级联架构:先“筛”后“检”(核心)
第一阶段:轻量预过滤(90%计算节省)
用运动差分+轻量CLIP快速剔除正常帧,只留可疑片段进入大模型。
把90%+的正常帧在前端过滤,避免大模型做无效计算。
第二阶段:VLM精检(只算异常)
对可疑片段做运动掩码提示(Motion Mask Prompting),让大模型只关注运动区域。
用规则偏差检测:学习正常行为规则,异常=偏离规则,不用枚举所有异常类型。
2. 关键优化点
动态图+时序推理(EventVAD):减少冗余计算,免训练、泛化强。
自蒸馏+数据增强(MAE):轻量模型蒸馏大模型知识,速度/精度双升。
多模态融合(Qwen3-Omni):视觉+音频+文本规则,降低误检、提升鲁棒性。
三、实测对比(主流算法)
算法 | 速度(FPS) | 加速倍数 | 精度(AUC/准确率) | 核心优势 | 部署场景 |
Cerberus | 57.68 | 151.79× | 97.2% | 级联+运动掩码 | 云端实时监控 |
自蒸馏MAE | 1655 | — | 高 | 极致轻量 | 边缘/嵌入式 |
LAVIDA | 中 | — | 76.45%–90.62% | 零样本、免异常数据 | 开放场景 |
EventVAD | 中 | — | SOTA | 免训练、动态图 | 通用安防 |
传统VLM | 0.38 | 1× | 97%+ | 高精度 | 离线分析 |
四、落地价值与场景
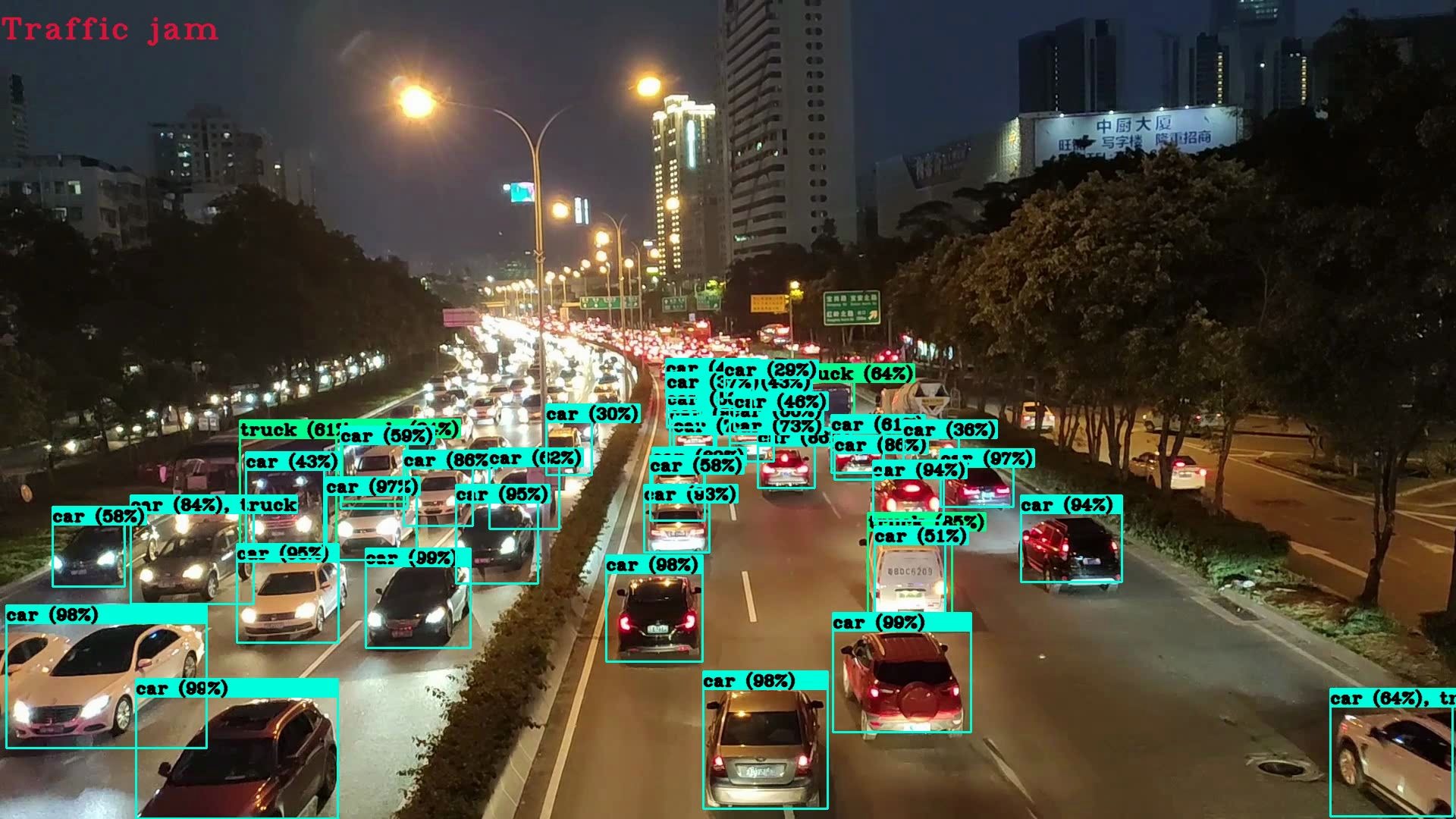
1. 安防监控:单GPU处理50+路摄像头,实时检测打架、闯入、遗留物,响应从秒级→毫秒级。
2. 工业质检:产线视频流1000+ FPS,实时检测缺陷、异常停机,效率提升100倍。
3. 交通/智慧城市:实时检测交通事故、拥堵、逆行,支撑智能调度。
4. 边缘设备:Jetson Orin上INT8量化,30+ FPS,本地实时处理、隐私安全。
五、实测结论
效率+精度不再矛盾:级联架构让100倍加速+97%+精度成为现实。
部署门槛大幅降低:单GPU可替代数十台传统服务器,成本降90%+。
从“事后回溯”到“实时预警”:真正实现视频异常的秒级响应。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















