
RK1828 本身不独立运行系统,搭配 RK3588/RK3576 主控 + RKNN3 SDK + RKLLM-Server,可本地暴露完全兼容 OpenAI 格式的 HTTP 接口,原有调用云端 OpenAI 的代码几乎不用修改,直接切换本地硬件推理,实现离线私有化替代云端 API。
1. 软件实现原理
1. RKNN3 Toolkit:将 Qwen、MiniCPM、LLaMA2、GLM 等开源大模型量化转换为 RKNN 推理格式,支持 INT4/INT8 压缩,适配 0.5B~7B/8B 模型;
2. RKLLM-Server 服务:板端启动轻量化推理服务,对外输出 /v1/chat/completions、/v1/completions、流式 SSE 输出、Function Call 等完整 OpenAI 标准接口;
3. 业务层无缝切换:前端 / 客户端仅修改 base_url 指向本地设备 IP,API 入参、返回结构、流式逻辑和云端 OpenAI 完全一致,无需重构业务代码。
2. 硬件基础能力(支撑本地 API 服务)
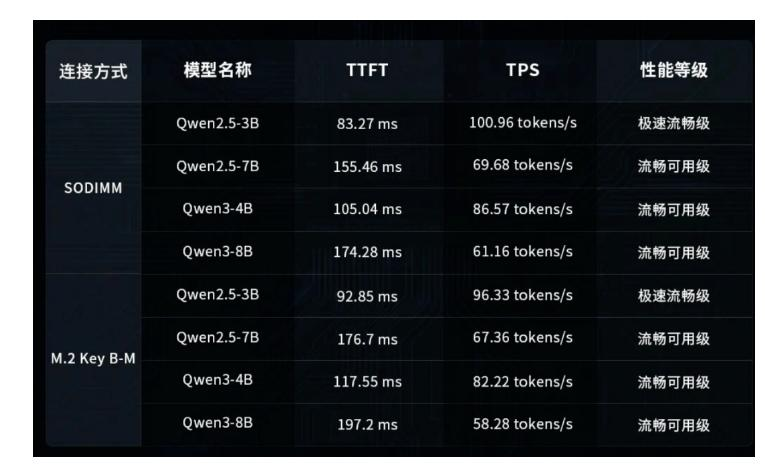
协处理器规格:20TOPS INT8 算力,5GB 片上 3D 堆叠 DRAM(RK1820 仅 2.5GB,RK1828 可稳定跑 7B 模型);
推理速度:Qwen2.5-3B 可达 95~105 tokens/s,首 token 延迟低至 90ms 内,满足实时对话、API 并发调用;
接口形态:M.2 Key B/M、SODIMM 两种算力卡,PCIe2.0 高速互联,整机功耗≤5W,7×24 小时稳定运行;
适配主控:RK3588(主流方案)、RK3576、国产工控 X86 小主机。
一、RK1828 低成本端侧替代云端 OpenAI 完整方案
方案 1:标准经济型(RK3588 主板 + M.2 RK1828 算力卡)
硬件清单 & 成本
主控:RK3588 8GB 内存开发板(千兆网、SSD 扩展)
算力扩展:M.2 接口 RK1828 AI 协处理器卡
存储:128GB SSD 存放量化模型
整机 BOM:800~1300 元,一次性投入,无后续 Token 计费
核心优势(对比云端 OpenAI)
1. 零持续调用成本:云端按 token 计费,高频场景月度成本数百至数万;RK1828 本地部署后永久免费推理;
2. 数据完全不出内网:对话、文件、图片不经过公网,满足政务、企业内网、隐私数据合规需求;
3. 低延迟离线可用:无网络波动、无跨区访问延迟,断网也能正常调用 AI 接口;
4. 接口 100% 兼容:原有 OpenAI SDK、Python/Java/JS 调用代码仅改服务地址即可复用;
5. 算力弹性扩容:多块 RK1828 并联,提升并发 API 请求承载量。
支持模型规格(本地 API 服务可加载)
轻量对话:0.5B~3B(MiniCPM、Qwen2.5-3B),并发 10 + 请求;
通用业务:7B(Qwen3-7B、GLM-Edge、Llama2-7B),单路流畅交互;
多模态 VLM:Qwen3-VL-4B 图文理解,兼容图像输入 API(替代 GPT-4V 基础能力)。
方案 2:超低成本极简方案(RK3576 + RK1828)
整机成本压至 600 元以内,适合小型门店、嵌入式终端、本地客服机器人,仅运行 1B~3B 轻量化模型,满足基础问答、文案生成、本地知识库检索。
方案 3:多机集群扩容(多 RK3588+RK1828 负载均衡)
企业高并发场景,多台 RK1828 节点部署统一 OpenAI 网关,实现 API 负载均衡,替代云端大模型集群,成本仅为云端服务器 1/4。
二、云端 OpenAI vs RK1828 本地 API 方案对比
对比维度 | 云端 OpenAI API | RK1828 端侧本地 OpenAI 兼容 API |
费用模式 | 按 Token 按量收费,长期成本高 | 一次性硬件投入,终身免费推理 |
网络依赖 | 必须联网,断网失效 | 完全离线可用,内网即可调用 |
数据安全 | 数据上传第三方云,存在泄露风险 | 数据本地存储,不出设备 / 内网 |
调用延迟 | 500ms~3s(网络波动) | 80~200ms 本地推理,稳定低时延 |
接口兼容 | 标准 OpenAI 接口 | 完全对齐 OpenAI v1 接口,代码零改造 |
并发上限 | 云端弹性扩容,付费提升并发 | 单 RK1828 支持 3~8 路并发,多卡可堆叠扩容 |
部署环境 | 公网服务,无法内网私有化 | 工业主板、嵌入式盒子、本地服务器均可部署 |
合规性 | 境外服务商,数据出境风险 | 国产全栈芯片,本地私有化符合数据合规要求 |
三、快速部署流程(打通 OpenAI 兼容 API)
1. 硬件组装:RK3588 主板 M.2 插槽插入 RK1828 算力卡,12V 独立供电;
2. 环境部署:烧录 RKNN3 配套 Linux 固件,安装 RKLLM-Server;
3. 模型量化:PC 端 RKNN-Toolkit 将开源 7B 模型 INT4 量化,拷贝至板端 SSD;
4. 启动本地 API 服务
# 启动兼容OpenAI的本地推理服务
./rkllm_server --model_path ./qwen3-7b-rknn --port 8000
5. 代码调用示例(替换云端 OpenAI)
from openai import OpenAI
# 仅修改base_url,其余代码完全不变
client = OpenAI(base_url="http://192.168.1.100:8000/v1", api_key="local")
resp = client.chat.completions.create(
model="qwen3-7b",
messages=[{"role":"user","content":"你好"}]
)
6. 业务对接:原有 ChatGPT 客户端、AI 工具、知识库系统直接对接本地 8000 端口 API。
四、适用落地场景(替代云端 OpenAI)
1. 企业内网知识库、本地客服机器人;
2. 工业设备、机器人离线 AI 交互;
3. 政务 / 医疗隐私数据本地 AI 处理;
4. 批量文案生成、本地文档解析(高频调用省大量云端费用);
5. 嵌入式终端、智能硬件自带本地大模型能力;
6. 私有化 AI Agent(OpenClaw 等工具本地部署,无需云端 Token)。
五、局限性说明
1. 模型上限:最高稳定运行 7B 参数模型,无法对标 GPT-4、GPT-4o 超大模型复杂推理;
2. 超高并发:单 RK1828 仅支持少量并发,千级并发需多硬件集群;
3. 超大文件处理:长文本、百万字文档处理速度弱于高端云端 GPU;
4. 开发门槛:需要基础嵌入式部署能力,模型量化、调优有少量技术成本。
六、总结
RK1828完整支持 OpenAI 标准 API 协议,通过 RKLLM-Server 实现本地兼容接口,是目前性价比极高的国产端侧低成本替代云端 OpenAI 方案。一次性硬件投入即可永久离线私有化推理,解决云端计费、数据安全、网络依赖三大痛点,适合绝大多数企业本地 AI、嵌入式离线大模型场景。
请用手机扫码查看分享内容
 需求留言:
需求留言:
领先的边缘智能产品与解决方案提供商






华北地区负责人:17340067106(毛经理)
华东地区负责人:17358670739(甘经理)
华南、华西地区负责人:19113907060(耿女士)
软件算法咨询:18982151213(刘先生)
四川省成都市武侯区天府五街花漾锦江JR大厦B座7层(总部)
 试用申请
试用申请

 硬件设备咨询
软件算法咨询
硬件设备咨询
软件算法咨询

 在线客服
在线客服

 回到顶部
回到顶部





 商城
商城


















